 最近实习之余,打算写一个用来自测用的的web目录扫描的小工具来重新学习以及应用一下python3.5的新特性――
最近实习之余,打算写一个用来自测用的的web目录扫描的小工具来重新学习以及应用一下python3.5的新特性――async/await。
为何要用协程
历史
其实协程早在python2就已经实现了(且历史上协程比线程出现的时间更早),以生成器Genarator的yield/send方式实现了一些功能,但是并不完全,后面py3有了Coroutine的语法糖,用@asyncio.coroutine和yield from来进行协程封装,到3.5后引入了async/await代替之前的用法,使得代码更加简洁易懂。本程序就是使用3.5后的语法async/await写的。
至于为何要用协程,这是一个很好的问题。
线程VS协程
我们都知道多线程写爬虫能够极大的提高效率,其原因在于爬虫的耗时基本在于网络的I/O等待,而多线程能够在I/O等待的时候调度,去运行另一个线程任务。如果假设两个任务各自需要10秒完成,其中有8秒的I/O等待以及2秒的CPU运算。采用串行的方法依次执行两个任务则需要――简单的相加――20秒。假设线程切换需要0.1秒,若是两个线程同时启动处理,则只需要2+0.1+2+8+0.1=12.2秒即可完成,这些都很好理解。
那么协程又是什么呢?
协程又称之为微线程、纤程,比线程更轻量级。我们可以先简单地将协程看成是一个可以下断点的函数,其与函数相似――共享线程的栈空间,有着自己的寄存器。一个线程可以有多个协程且协程的调度代价比线程低很多。
在我个人理解看来,协程是一个下了断点的函数。在运行到断点之前,是不能参与协程调度的,而到达断点的时候,若碰上了I/O等阻塞则可以跳转到另外一个协(函)程(数)执行它的代码。由此看出,协程的调度:
一、调度是由程序员自己控制的;二、调度是非抢占式的。接着上面的例子,若我们将断点定在I/O阻塞时刻前,然后跳转到另一个协程去执行它的任务,则同样的我们假设协程调度只需要0.01秒,则总的时间是2+0.01+2+8+0.01=12.02秒。看起来是不是和线程的过程差不多?
咱们上面讨论的是单核的情况,可线程可以同时在多核并发运行的,当我们核>=2时,咱们任务只需要10秒即可完成,而重点是,协程的调度只能在一个线程内进行调度,也就是说只能发挥一个核的作用。
是不是瞬间感到很鸡肋? 那我为啥还要用协程呢
The Infamous GIL
这是由于Cpython中GIL――全局解释锁(Global
Interpreter
Lock)的存在,使得我们最熟知、常用的python版本Cpython并不能使得多线程实现并行化,反而用多核跑多线程比单核跑多线程来的效率更低。(其详细的原因请看这位外国大佬David
Beazley的PyCON的PPT,讲得十分之好,有时间我翻译过来再写一篇博客专门讲python的GIL)
故python线程并不能发挥多核的优势,而在单核方面又没有协程的效率高,所以选协程写并非仅仅心血来潮。
另外原因在于线程需要对争议资源进行加锁,防止发生不安全的更改以操作,对写扫描输出日志也需要进行加锁操作,比较麻烦。而协程并没有这样的顾虑,它对资源并没有争议,故也不需要加锁,程序的逻辑就会很清晰,很好实现。
在此多说一句,Python的多线程也并非向我说的那样”一无是处“,对于CPU密集型处理(CPU-bound),抢占式处理如GUI的响应都是协程的痛点而线程却能够胜任之。
而对于I/O密集型的任务,协程则能最大限度的发挥出单核的能力,加之以多进程,实现多核并行计算,使得协程大放异彩。
这么说来,协程是需要自己进行调度的,听起来就比线程麻烦,毕竟线程可以依靠操作系统自成一套的调度。python2中的gevent以及python3中的async库将协程调度封装成库,自动识别I/O等阻塞操作,随后进行协程切换调度。我们只需要知道断点放在哪以及功能如何实现就好了。
那么接下来就是介绍本菜写的web目录扫描器――wscan了
wscan
思路
wscan是一个基于协程(asyncio、aiohttp)的网站目录扫描器,用于网站路径的收集以及探测,主要分为两个功能: + 路径爆破探测 + 网站目录爬取
然后整理成一张树图展现出网站的结构以及各个路径的响应情况
对于路径爆破,我们的思路很快就能出来 1. 准备个爆破字典,取出一个爆破路径
2. 请求Target URL+爆破路径,取回响应码 3.
对响应码进行分析并分类显示结果 4. 开始下一个路径的爆破
嗯,就跟如何把大象放进冰箱一样简单的三步走 这是基本的串行处理,但是咱们都知道,这样的速度是远远不够的。 如果改用协程写,那么我们想要控制这么多个协程,采用任务队列是一个很好的方法。(我是直接拿用aiohttp的Queue来用的) 我们将待处理的路径丢进队列,然后开N个协程不断从队列中获取任务,一旦某个协程遇到I/O阻塞则切换到另外一个协程继续运行。所以我们可以将“断点”设置在请求和获取响应之间。(生产者-消费者模型) 每个协程的流程图如下:
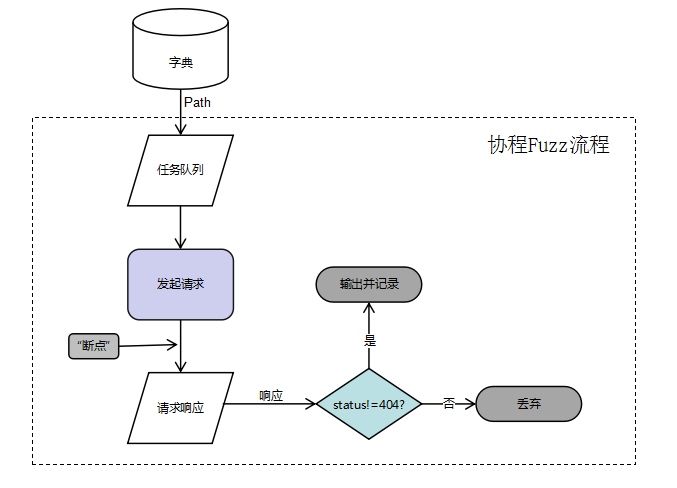
Fuzz的这一部分逻辑十分明了,所以我们能很容易地将其写出来。再多说一句,为了代码的重用性和封装性,应该考虑此时发起请求的协程以及管理其行为的函数与接下来的网站目录爬取兼容,实现代码重用。
接下来就是网站目录的爬取,以及绘制一个网站目录结构。
一般网站的目录及资源存在于<a>标签的href属性,301,302,307跳转的Location中以及一些资源文件如<script>、img标签的src等等
。 我们可以以如下的方式进行页面爬取: 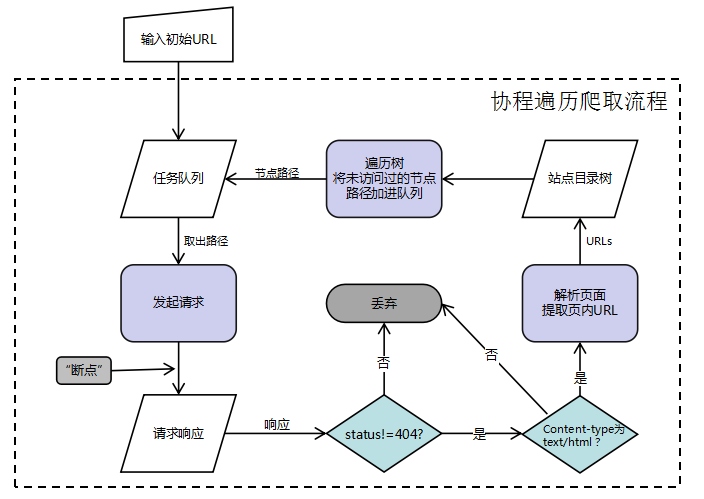
细节
说一下一些细节:
- 由于咱们的目录是一个多叉树结构,所以我用
dict作为子节点集合写了个结构树类以及对应节点类,作为咱们的基本数据结构。 之前是考虑到同一目录下子节点不可重名,所以一开始不采用list而采用了set作为子节点集合,毕竟set可以去重,键唯一,很符合这一个设定,然后用节点类的名字作为set里面__hash__的键,实现了一个简单的文件目录树结构。 后来直到需要设定子节点集合里面的节点属性时就发现set找元素并不好找,需要遍历一次才能找到,故决定改用采用同时具有引索又有以上属性的dict实现。嗯,真香。 然后遍历树节点取其路径就可以采用很多方法了,深度、广度优先都可以。但是当我们想将树的结构输出(类似于tree命令)时,深度优先是最合适的。(可以动手试一下) - 还有一些异常处理以及URL的拼接是比较麻烦的,因为页面提取到的URL可能是相对路径也可能是其他外联页面的地址(不属于我们爬取的范围),也有可能是类似于
../../../cms/admin.php等比较麻烦的相对路径,所以我直接使用了python3标准库urllib.parse中的urlparse以及urljoin来实现以上功能。 为了爬虫能够"健康"地爬取页面,加入了随机User-agent功能以防止被ban掉(当然,挂代理池是最吼的) - 最后模仿github上的一个项目
dirsearch支持了拓展后缀名,以便扫描出适合的后缀名路径。 - 本来想加入端口扫描的功能,然后发现直接socket进行TCP连接的方式判断开放与否不仅速度慢并且会留下痕迹,而且我也没准备啥指纹去匹配端口所对应服务,现阶段只是一个探测开放性的一个小功能,还是待我完善之后再加进去吧
附上代码目录结构:
wscan
│ wscan.py
├─fuzz
│ │ dirList.txt #Fuzz路径文件
│ └─ user_agent.txt # 请求所需的User-agent 列表
└─lib
├─controller
│ └─ Controller.py # 主控制流程
├─exception
│ └─ ScanException.py # 异常处理
├─io
│ │ Argument.py # 参数接收相关
│ └─ ColorOutput.py # 输出相关
├─portscan
│ └─ portScan.py # 端口扫描(由于功能有点简陋,还未加进主程序)
└─tree
│ DirTree.py # 路径树
└─ Node.py # 节点Install
学习了一下怎么上传pypi,终于能够方便地安装了
$ pip install wscan Usage
使用方式: Type -h for
help
$ wscan [-u URL] [-f] [-m] [Extend options]-u URL: 目标URL
-f: 启用Fuzz功能
-m: 爬取网站获取网站目录结构
-b BASE: Fuzz的前缀地址 e.g -b /cms/app. 然后将会在
http[s]://host/cms/app/的基础上进行爆破-e EXTEND: 爆破的后缀名,默认为php
-max NUM: 最大协程数
-404 NOT_FOUND: 自定义404标识, 爬取和Fuzz时会正则匹配该值来判断是不是自定义404页面,减少误报. e.g. "Not found"
--s: 爬取静态资源(目前只支持图片
img和JSscript)-v, -vv: 详细的输出信息
-h: 帮助
说了这么多 最后来一个演示小动画吧:)

欢迎下载使用并提出意见 wscan-Github地址